Thinking Tokens: что главное в рассуждениях языковых моделей?
11/25/2025

Модели семейства OpenAI o1, DeepSeek R1, QwQ, а затем и все остальные произвели очередную мини-революцию в сложных рассуждениях; благодаря им модели резко продвинулись в практически всех видах интеллектуальной деятельности. Но что происходит внутри этих моделей, когда они “думают”? Какие части их рассуждений самые важные? Новая работа исследователей из Shanghai AI Lab Qian et al. (2025) приподнимает завесу тайны, обнаруживая информационные пики — критические моменты в процессе рассуждения, которые соответствуют особым “thinking tokens”. Мы можем посмотреть, что это за токены, и, более того, понимание этих механизмов имеет практический смысл: авторы предлагают новый простой, но эффективный метод, улучшающий качество рассуждений без дополнительного обучения.
Как измерить “прогресс мысли”: взаимная информация
Как понять, продвигается ли модель к правильному ответу на каждом шаге рассуждения? Авторы предлагают элегантный подход: измерять взаимную информацию (mutual information, MI) между внутренним представлением модели на каждом шаге и правильным ответом.
Математические основы
Взаимная информация — это мера того, сколько информации одна случайная величина содержит о другой. Формально говоря, для двух случайных величин X и Y
![\[I(X; Y) = \sum_{x \in X} \sum_{y \in Y} p(x,y) \log \frac{p(x,y)}{p(x)p(y)},\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-1dbe002d3b4df2453b18f742dbe02aca_l3.svg "Rendered by QuickLaTeX.com")
ну или, соответственно, в непрерывном случае
![\[I(X; Y) = \int_Y \int_X p(x,y) \log \frac{p(x,y)}{p(x)p(y)} \, dx \, dy.\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-194d1847b64c5002cfa51e1bf954e47a_l3.svg "Rendered by QuickLaTeX.com")
Взаимную информацию также можно выразить через энтропию:
![\[I(X; Y) = H(X) - H(X|Y) = H(Y) - H(Y|X),\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-45ffcccdeaa6b56e9081b7a09a0c7ce5_l3.svg "Rendered by QuickLaTeX.com")
где  — энтропия
— энтропия  , а
, а  — условная энтропия при условии
— условная энтропия при условии  . Интуитивно говоря, взаимная информация измеряет, насколько знание одной величины уменьшает неопределённость относительно другой. Eсли
. Интуитивно говоря, взаимная информация измеряет, насколько знание одной величины уменьшает неопределённость относительно другой. Eсли  , величины независимы, а если
, величины независимы, а если  , они полностью детерминированы друг другом.
, они полностью детерминированы друг другом.
Взаимная информация представлений с ответом
В нашем случае вопрос звучит так: сколько информации о правильном ответе содержится в текущем внутреннем состоянии модели? Если MI высокая, значит, модель на верном пути, если низкая — ещё не нащупала решение.
И здесь появляется главное открытие работы: при анализе моделей DeepSeek R1 и QwQ авторы обнаружили пики взаимной информации (MI peaks) — моменты, когда взаимная информация резко возрастает. Эти пики:
- разбросаны неравномерно по траектории рассуждения (они появляются не через фиксированные интервалы),
- составляют всего 0.5-5% от всех шагов и, главное,
- появляются именно в момент “прорывов” в рассуждении.
Вот как выглядит график взаимной информации в процессе рассуждения для небольших открытых моделей:
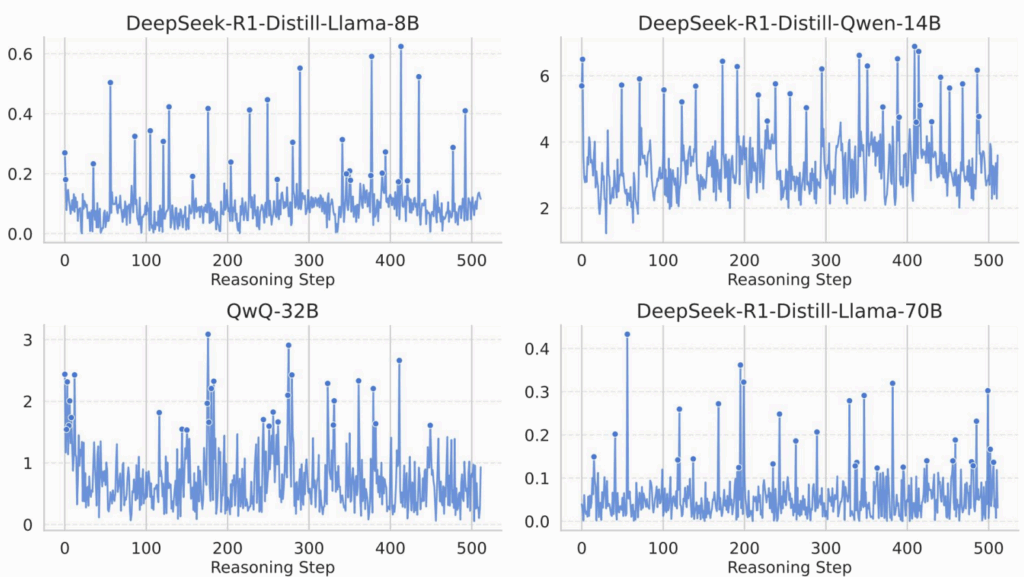
Технически говоря, MI в пространстве такой высокой размерности подсчитать трудно, и авторы измеряют не MI напрямую, а её прокси, критерий независимости Гильберта-Шмидта (Hilbert-Schmidt Independence Criterion, HSIC) — непараметрический метод оценки зависимости через ядра; впрочем, в это нам углубляться уже не обязательно, получается хорошая аппроксимация MI, и нам этого достаточно.
Теоретические оценки
Интуиция понятна, но почему высокая MI должна коррелировать с правильностью ответа? Авторы доказывают две теоремы, устанавливающие количественную связь между накопленной MI и вероятностью ошибки модели. Углубляться в их доказательства я не буду, но формулировку (общую, там одна теорема даёт нижнюю оценку, а другая верхнюю) приведу.
Пусть  — последовательность представлений модели,
— последовательность представлений модели,  — правильный ответ,
— правильный ответ,  — предсказание модели,
— предсказание модели,  — вероятность ошибки. Тогда
— вероятность ошибки. Тогда  можно оценить с двух сторон (это и есть две теоремы в статье):
можно оценить с двух сторон (это и есть две теоремы в статье):
![\[p_e \geq \frac{1}{\log(|Y| - 1)} \left[ H(y) - \sum_{j=1}^T I(y; h_j \mid h_{<j}) - H_b(p_e) \right],\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-c85485e15e97ff6d62455086ddb086d1_l3.svg "Rendered by QuickLaTeX.com")
![\[p_e \leq \frac{1}{2} \left[ H(y) - \sum_{j=1}^T I(y; h_j \mid h_{<j}) \right],\]](https://blog.sergeynikolenko.ru/wp-content/ql-cache/quicklatex.com-c1919722ec08f877b42bc746d1819134_l3.svg "Rendered by QuickLaTeX.com")
где  — размер пространства возможных ответов,
— размер пространства возможных ответов,  — энтропия распределения правильного ответа,
— энтропия распределения правильного ответа,  — условная MI между и
— условная MI между и  при условии предыдущих представлений,
при условии предыдущих представлений,  — энтропия вероятности ошибки.
— энтропия вероятности ошибки.
Интуитивно говоря, это показывает, что вероятность ошибки ограничена снизу и сверху выражениями, содержащими суммарную условную MI, т.е. полную информацию о правильном ответе, накопленную моделью по ходу рассуждения. Чем она больше, тем меньше и нижняя, и верхняя границы в формуле выше, то есть обе границы стягиваются к нулю: чем больше модель узнала о правильном ответе, тем меньше вероятность ошибки.
Соответственно, пики MI быстро “набирают” взаимную информацию в эту сумму, в критические моменты модель делает резкие скачки в суммарной MI, и поэтому такие пики особенно важны: в эти моменты происходит основной “информационный прогресс” к правильному ответу.
Но что же это за пики такие? Какие токены им соответствуют?
Thinking Tokens: маркеры озарения
Что же происходит в эти моменты информационных пиков? Авторы применили изящный трюк: декодировали внутренние представления обратно в токены, чтобы увидеть, какие именно слова соответствуют high-MI состояниям. А именно, смотрят на признаки на последнем слое модели и жадно выбирают токен с максимальной вероятностью.
Зачем так сложно?
Здесь, кстати, возникает ещё один вопрос: зачем так усложнять? Модель же генерирует токены на своём scratchpad (в цепочке рассуждений), почему нельзя просто посмотреть, какие токены совпадают с моментами MI peaks? Проблема в том, что токен на scratchpad и внутренние представления сдвинуты: когда модель порождает последовательность токенов  , на шаге
, на шаге  модель имеет представление
модель имеет представление  . Это представление используется для предсказания следующего токена
. Это представление используется для предсказания следующего токена  , но пик MI в
, но пик MI в  отражает информацию, накопленную до порождения , и он может быть связан с информацией, полученной из
отражает информацию, накопленную до порождения , и он может быть связан с информацией, полученной из  или раньше. Поэтому просто взять токен на позиции пика MI недостаточно — он может быть “следствием” пика, а не его “содержанием”; а вот в представлениях уже действительно содержится вся информация, используемая далее моделью.
или раньше. Поэтому просто взять токен на позиции пика MI недостаточно — он может быть “следствием” пика, а не его “содержанием”; а вот в представлениях уже действительно содержится вся информация, используемая далее моделью.
Какие это токены?
Но хватит уже нагнетать саспенс — что за токены-то получаются? Результат очень красивый, на мой взгляд неожиданный, но интуитивно абсолютно понятный. В моменты MI peaks модель генерирует так называемые thinking tokens (токены размышлений); это слова, выражающие:
- рефлексию: “Hmm”, “Wait”, “Hold on”;
- логические переходы: “Therefore”, “So”, “Thus”;
- самопроверку: “Let me reconsider”, “Actually” и т.д.
Вот такие примерно слова там встречаются:
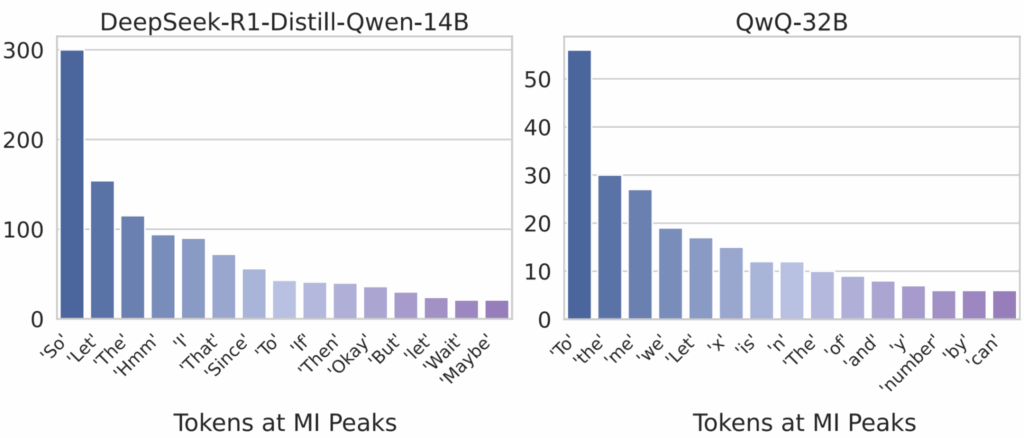
Оказывается, что все эти “hmm” и “wait” в рассуждениях моделей — это не просто языковые украшения или артефакты обучения, а наоборот, самые главные токены! Они маркируют критические моменты, когда модель обнаруживает ошибку в рассуждении, меняет стратегию решения или делает ключевой логический переход.
Экспериментальное подтверждение
Чтобы окончательно удостовериться, что эти токены действительно важны, авторы провели контролируемый эксперимент: запретили модели генерировать thinking tokens, устанавливая их вероятность в ноль.
И вот результат:

Оказывается, что если подавлять thinking tokens, то без первых двух-трёх таких токенов модель ещё обойдётся (заменив их на другие thinking tokens — этот эффект авторы тоже отметили), а потом начнётся очень серьёзное падение качества: на 20-30% на сложных задачах! При этом на зелёной кривой, показывающей подавление случайных токенов, не видно почти никакого эффекта.
Это подтверждает, что thinking tokens действительно критически важны для успешных рассуждений, это не просто корреляция. Получается, что моделям нужна эта возможность выразить моменты рефлексии и логических переходов, и без слов вроде “hmm” или “maybe” модель просто теряет способность к сложным рассуждениям…
Авторы также вручную просмотрели примеры и обнаружили, что после thinking tokens часто следуют фразы вроде:
- “Wait, let me think differently. Let’s denote…” (смена стратегии);
- “Hmm, so I must have made a mistake somewhere. Let me double-check…” (обнаружение ошибки);
- “Therefore, combining these results…” (синтез информации) и так далее.
Representation Recycling: давай подумаем ещё
Теперь, когда мы поняли важность MI peaks и thinking tokens, возникает вопрос: как использовать это знание для того, чтобы улучшить рассуждения моделей?
Что значит “подумать ещё”?
Интуитивно кажется, что есть смысл предложить модели подумать подольше. Здесь Qian et al. предлагают интересную идею, но прежде чем объяснять её детально, давайте сами подумаем: какие вообще есть варианты попросить LLM “подумать побольше”?
Во-первых, можно запустить модель несколько раз с разными random seeds, получить несколько вариантов рассуждений и выбрать лучший из них, например, через мажоритарное голосование или верификатор. Это известная идея, и известно, что она может сработать: ещё на заре chain-of-thought методов начали применять self-consistency такого рода (Wang et al., 2022). Но это не получится опустить на уровень отдельных токенов: LLM ведь сама по себе детерминированная модель, сэмплирование происходит только на последнем шаге, так что если уже сгенерированный префикс зафиксирован, то на следующем токене распределение не изменится.
Во-вторых, можно продлить рассуждения, искусственно добавив подобный thinking token в конце. Например, после порождения ответа просто добавить в рассуждения модели фразу вроде “Are you sure? Let me double-check…” и продолжить порождение. Это тоже уже известный метод, так делали Mueninghoff et al. (2025) в работе про модель s1, ту самую рассуждающую модель, обученную за $50. Но это тоже не точечное вмешательство.
В-третьих, в критические моменты (например, в момент порождения thinking tokens) можно увеличить температуру сэмплирования, чтобы исследовать больше вариантов. Это уже направленное вмешательство в нужный момент, но это совсем не та интервенция, которая нам нужна: мы бы хотели, чтобы модель “углубилась” в текущую линию рассуждения, а высокая температура, наоборот, будет “разбрасывать” внимание модели.
Representation Recycling
Вместо всего этого Qian et al. предлагают Representation Recycling (RR) — метод, который звучит почти парадоксально: когда мы на текущем представлении внутри модели (после некоторого блока трансформера  ) фиксируем пик MI, нужно взять это внутреннее представление и прогнать его ещё раз через тот же блок трансформера , получив “углублённое” представление
) фиксируем пик MI, нужно взять это внутреннее представление и прогнать его ещё раз через тот же блок трансформера , получив “углублённое” представление  .
.
Может показаться, что это бессмысленно: зачем через одни и те же веса детерминированного трансформера прогонять один и тот же вход два раза?
Однако хотя веса одинаковы, контекст меняется! В первом проходе self-attention в видит  (представление предыдущего слоя), а во втором проходе (recycling) self-attention видит
(представление предыдущего слоя), а во втором проходе (recycling) self-attention видит  , результат первого прохода, в котором эти представления уже один раз “посмотрели друг на друга”. Понятно, что формально это новый вход, и выход будет тоже другой, но это и интуитивно имеет смысл.
, результат первого прохода, в котором эти представления уже один раз “посмотрели друг на друга”. Понятно, что формально это новый вход, и выход будет тоже другой, но это и интуитивно имеет смысл.
Думаю, верная аналогия здесь в том, чтобы как будто “прочитать текст два раза”. Первое чтение даёт общее понимание, а второе чтение того же текста, при котором вы уже заранее знаете, что в нём есть, будет более детальным: вы замечаете детали и связи, которые пропустили в первый раз. Аналогия, конечно, не совсем точная — для нашего человеческого чтения всё-таки принципиально то, что мы читаем последовательно, и во второй раз главная новая информация придёт от того, что мы уже видели, что будет дальше, а у LLM такого эффекта нет — но думаю, что она всё-таки что-то проясняет.
В реальности такая повторная обработка имеет смысл для верхних слоёв трансформера (примерно 20-30 слои в 70B моделях, или 15-20 слои в 8B моделях). И эмпирически оказывается, что RR даёт существенное улучшение во всех изученных рассуждающих моделях:
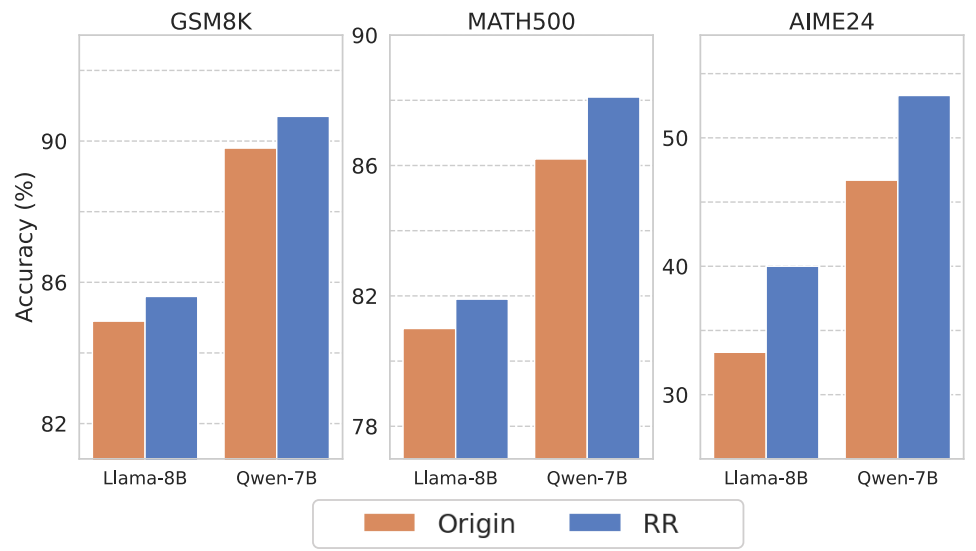
Замечания о методе RR
Ещё два замечания:
- в момент применения модели мы, конечно, не знаем ответа и не можем подсчитать MI, но для этого и было всё предыдущее исследование: мы будем применять RR, когда модель порождает тот или иной thinking token;
- очевидно, что повторно прогонять представления можно не только во второй раз, но и в третий, четвёртый и так далее, но здесь авторы пишут, что улучшения тут же пропадают, а затем начинается даже откат улучшений — возможно, начинается оверфиттинг к конкретному получившемуся представлению.
Замечу ещё, что хотя такой подход, конечно не бесплатный в вычислительном смысле — дополнительный проход через блок трансформера добавляет вычислений — здесь очень важно, что повышенную цену мы платим только в моменты появления thinking tokens, то есть 5-10 раз за всю цепочку рассуждений, а не на каждом шаге, так что на самом деле цена фактически пренебрежимо мала. В общем, интересный новый подход к test-time scaling, который очень легко реализовать и который, кажется, действительно улучшает результаты.
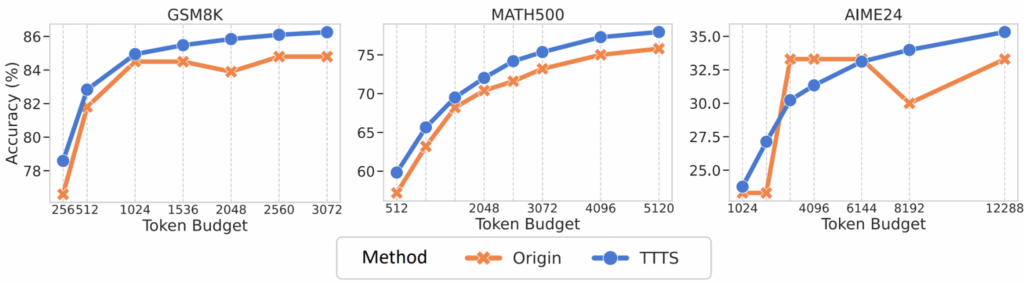
Test-time scaling через добавление thinking tokens
Идею Mueninghoff et al. (2025) из работы про s1 здесь авторы, впрочем, тоже изучают; она теперь, видимо, официально будет называться TTTS (Thinking Token based Test-time Scaling). Это та же идея — добавлять в конец рассуждений thinking tokens и продолжать думать до исчерпания вычислительного бюджета — но теперь, в отличие от s1:
- появилось теоретическое обоснование через пики MI;
- выбор таких дополнительных промптов стал лучше и более автоматизирован: для новой модели можно просто собрать статистику по характерным для неё thinking tokens;
- теперь TTTS можно комбинировать с RR.
Улучшения от такого TTTS не гигантские, но заметные и, главное, устойчивые:
Обзор других похожих работ
Течение этого поста было логичным и даже имело некоторую повествовательную арку, так что прерывать её на обзор related work не хотелось, и (небольшую) обзорную часть я перенёс в конец. Однако несколько работ, которые дают важный контекст других подобных исследований, я всё-таки упомяну.
Safety tokens
Lin et al. (2024) обнаружили удивительный феномен при изучении AI alignment. Вопрос стоял так: как именно alignment (в данном случае имеется в виду обучение моделей отказываться от потенциально вредных запросов) работает на механистическом уровне? Авторы проанализировали внутренние представления и паттерны внимания aligned моделей (например, LLaMA-2-Chat) при таких вредоносных запросах.
Главное открытие было в том, что aligned модели научились порождать специальные “safety tokens” в начале ответа: “I’m sorry”, “I cannot”, “However”, “I apologize” и так далее. После порождения этих токенов паттерны внимания моделей меняются очень сильно, последующие токены обращают на них очень много внимания, и модель “блокируется” и переходит в режим отказа.
Эффект оказался сильным и устойчивым. Например, если искусственно удалить “I’m sorry” из начала ответа и продолжить порождение, модель может выдать вредоносный контент. И даже базовая модель, до всякого alignment, если начать её ответ с “I apologize”, стремится продолжить в “безопасном” духе.
Почему safety tokens — это плохо
Qi et al. (2025) продолжили идеи Lin et al. во вполне логичном направлении: если alignment оказался настолько “поверхностным”, что зависит от нескольких safety tokens в начале, значит, его легко обойти? И действительно, легко: можно добавлять специальные окончания в промпты (adversarial suffixes), которые перебивают влияние safety tokens, а можно просто задать вопрос на нескольких языках, ведь safety tokens обычно обучены только на английском.
Авторы, впрочем, дают и конструктив и предлагают методы “deep alignment”: как заложить безопасность в представлениях модели, а не только в начальных токенах. В это я углубляться не буду, только ещё раз отмечу, что “безопасность” здесь понимается в весьма узком и специфическом смысле: как заставить модель не отвечать на потенциально вредоносные запросы. Это не всё AI safety, а одна его конкретная (и довольно, так сказать, mundane) компонента.
Critical tokens matter: как использовать важные токены для обучения
Работа Lin et al. (2024) тоже очень похожа на нашу сегодняшнюю: она напрямую исследует критические токены в контексте рассуждающих моделей, но с другой стороны. Здесь предположение в том, что в chain-of-thought reasoning не все токены одинаково важны: некоторые токены представляют собой что-то важное (здесь речь скорее о важных логических шагах, до “hmm” и “wait” здесь авторы не дошли), другие — просто филлер.
Авторы предлагают так называемый метод token-level contrastive estimation: взять правильные и неправильные рассуждения для одной и той же задачи, поточечно сравнить их, найти discriminative tokens, то есть места, где правильные и неправильные chains различаются, а потом обучить модель с повышенным весом ошибки именно на таких discriminative tokens.
Модели, обученные с token-level contrastive loss, действительно в итоге значительно лучше рассуждают, и действительно обучаются “обращать внимание” на критические логические шаги. Здесь, конечно, кроме очевидного сходства бросается в глаза то, что обе идеи вполне можно совместить: давайте попробуем делать contrastive estimation для токенов с высокой MI, или для уже выделенных thinking tokens. Интересно было бы попробовать.
Другие похожие исследования
Про критические токены вроде всё, но есть ещё несколько работ, которые похожи на эту по другим признакам. Подробно обозревать их уж не буду, но кратко назову:
- Ton et al. (2024) тоже используют теорию информации и в частности взаимную информацию с ответом для анализа chain-of-thought reasoning; правда, они не спускаются на уровень токенов и просто отмечают, что chain of thought увеличивает MI между входом и выходом модели, даёт дополнительную информацию о правильном ответе, особенно в случае self-consistency CoT (нескольких порождений);
- Snell et al. (2024): работу Mueninghoff et al. (2025) я обсуждал в основном тексте, а это ещё одна статья о том, что test-time scaling может быть даже полезнее, чем масштабирование по числу параметров;
- Zou et al. (2023): всё это, конечно, большое направление с кучей разных статей, но, например, эта довольно характерная работа предлагает framework для понимания и контроля поведения AI-моделей через управление их внутренними представлениями; мыслеконтроль как он есть, и в каком-то смысле RR является его частным случаем.
Заключение
Работа Qian et al. (2025) даёт красивый пример того, как очень простой вопрос и очень прямолинейное по сути исследование привели к важному продвижению в понимании механизмов работы рассуждающих моделей, а затем и к практическим улучшениям. Последовательность выглядит так:
- интересное наблюдение: в траекториях рассуждений современных LRM появляются пики взаимной информации с правильным ответом;
- интерпретация: эти пики соответствуют thinking tokens — токенам рефлексии и логических переходов;
- теория: между суммарной накопленной MI и вероятностью ошибки есть теоретическая связь, которая формализует нашу интуицию о важности этих моментов;
- практика: Representation Recycling и TTTS используют найденные thinking tokens для улучшения качества рассуждений;
- валидация: методы работают, рассуждения становятся лучше, и всё это ещё раз подтверждает правильность нашего новообретённого понимания.
Особенно ценно, что оба предложенных метода (RR и TTTS) — сугубо test-time: они не требуют переобучения модели, только модификацию процесса её применения. Это значит, что их легко применить к уже существующим рассуждающим моделям; для RR, правда, нужен доступ ко внутренностям модели, но не более того, переобучать всё равно ничего не надо. При этом улучшения довольно существенные: +20% на сложных математических задачах из AIME — это очень серьёзный прогресс для метода, который в реализации занимает буквально десяток строчек кода.
Есть и много открытых вопросов для дальнейших исследований. Почему пики MI возникают именно в эти моменты, а не в другие? Можно ли предсказать их появление заранее? Можно ли явно тренировать модели на максимизацию таких пиков, или создавать для них “оптимальные” thinking tokens? И самый интересный вопрос: какие ещё можно найти способы использовать эти high-MI representations, помимо прямого recycling?
Но уже сейчас понятно, что thinking tokens — это не просто лингвистические артефакты, а фундаментальная часть архитектуры рассуждений современных языковых моделей. Модели действительно “думают” в эти моменты, и мы теперь можем это измерить, объяснить и улучшить.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!