Mixture-of-Recursions: думаем над токенами рекурсивно и адаптивно
7/30/2025

AI-модели растут, “горький урок” и законы масштабирования всё ещё работают, но растущие вычислительные требования становятся всё более неподъёмными даже для гигантов рынка. Один из ключевых вопросов современного AI — как сделать то же самое эффективнее. В этом посте я расскажу о новом подходе, который очень элегантно сочетает сразу несколько известных идей и кажется весьма перспективным.
Три пути к эффективности
Исследователи из KAIST и Google Bae et al. (2025) представили новую идею под названием Mixture-of-Recursions (MoR, смесь рекурсий). Чтобы понять, что она делает, давайте сначала вспомним три основные стратегии повышения эффективности трансформеров без радикального изменения архитектуры (без перехода на Mamba-подобные модели, например):
- Mixture-of-Experts (MoE, смесь экспертов) добавляет разреженность активаций при инференсе: в модели есть много подсетей-экспертов, и специальный роутер выбирает, какую подсеть использовать для каждого токена на каждом MoE-слое; в результате получается, что параметров у сети очень много, но на каждый токен активируется только небольшое их подмножество; MoE — это огромная наука, о которой я, надеюсь, скоро расскажу гораздо подробнее, но в общем все современные гигантские модели устроены именно так;
- layer tying (связывание слоёв) уменьшает число параметров за счёт повторного использования одних и тех же весов в разных слоях; эта стратегия используется как минимум с времён Universal Transformers (Dehgani et al., 2018) и продолжает появляться до сих пор (Gholami, Omar, 2023; Bae et al., 2025b);
- early exiting (ранний выход) тоже добавляет разреженности, как и MoE, но за счёт остановки обработки на ранних слоях для более простых токенов; идея восходит к Depth-adaptive Transformers (Elbayad et al., 2020) и продолжает развиваться; например, недавно появилась архитектура LayerSkip (Elhoushi et al., 2024).
Традиционно исследователи использовали только один из таких подходов зараз, особенно учитывая, что эти стратегии нацелены на разные вещи: связывание весов экономит память, но не время инференса, а разреженные активации или ранние выходы, наоборот, никак не уменьшают требуемую память. MoR утверждает, что можно и нужно решать обе проблемы одним архитектурным решением. Давайте сначала рассмотрим непосредственных предшественников и идейных вдохновителей MoR, а потом перейдём и к самой статье.
Mixture-of-Depths и рекурсивные трансформеры
Первым важным предшественником этой работы стала идея Mixture-of-Depths, предложенная исследователями из Google DeepMind (Raposo et al., 2024). Они ввели маршрутизацию на уровне токенов для адаптивных вычислений. В то время как MoE-модели обучают маршрутизатор выбирать между разными подсетями (экспертами), Mixture-of-Depths обучает маршрутизатор выбирать, использовать ли слой или перейти непосредственно к остаточному соединению:
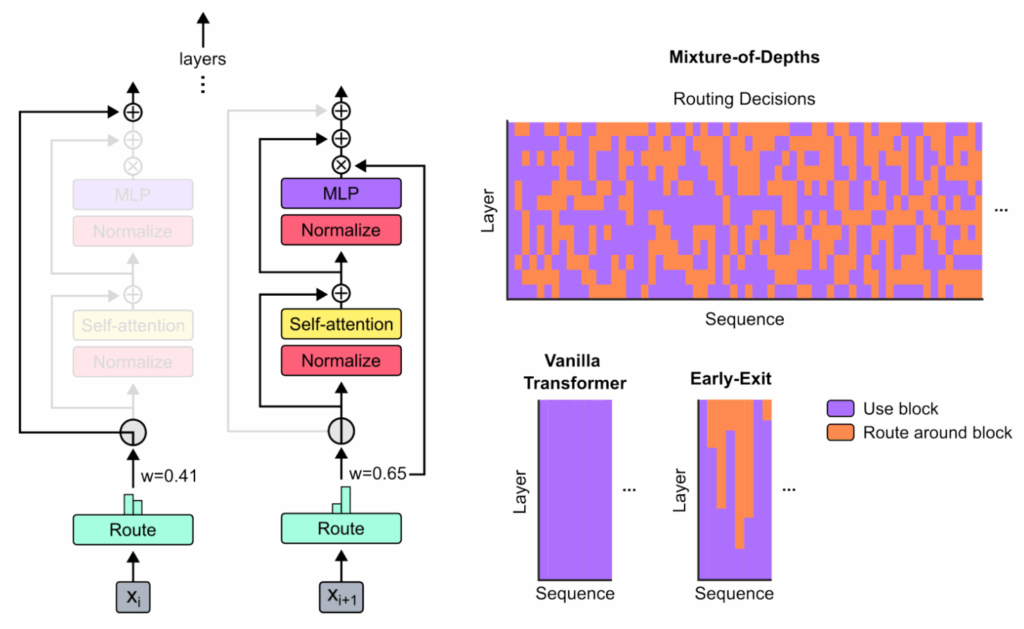
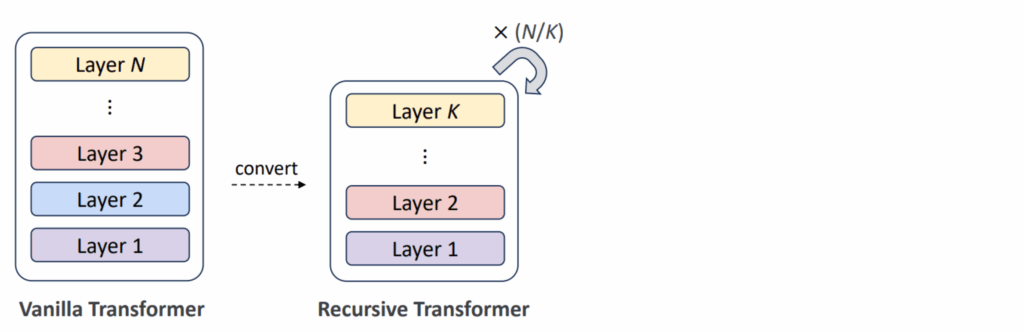
А если объединить связывание слоёв и ранние выходы, получатся рекурсивные трансформеры (Recursive Transformers, Bae et al., 2025b) — модели, которые повторяют один блок из K слоёв несколько раз, создавая зацикленную архитектуру. Например, вместо 30 уникальных слоёв в рекурсивной модели будет всего 10 слоёв, которые применяются трижды, что, соответственно, втрое сокращает число параметров:
Но какой смысл применять одни и те же слои несколько раз? Ранний слой, предназначенный для работы с самими токенами, был бы бесполезен при применении к их глобальным семантическим представлениям в более высоких слоях. И действительно, было бы лучше иметь способ модифицировать слои по мере продвижения. Поэтому Relaxed Recursive Transformers (RRT, релаксированные рекурсивные трансформеры) добавляют небольшие LoRA-адаптеры к слоям, которые можно обучать отдельно для каждой итерации цикла:
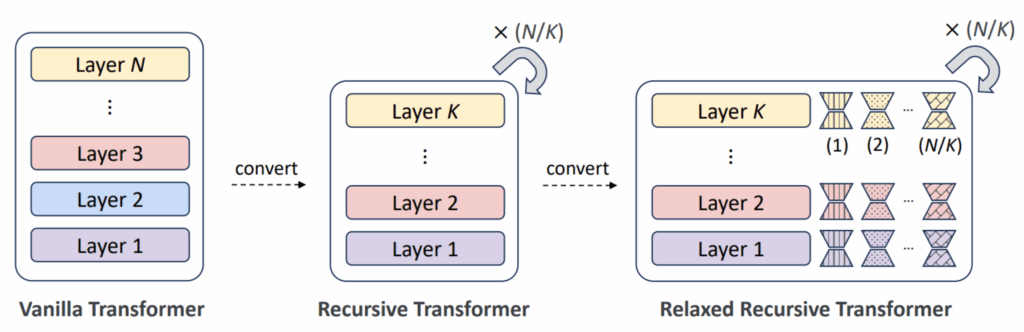
Bae et al. (2025b) обнаружили, что их RRT стабильно превосходят стандартные архитектуры: если дистиллировать предобученную модель Gemma 2B в рекурсивную Gemma 1B, результаты получаются намного лучше, чем при дистилляции в обычную Gemma 1B, и приближаются к результатам исходной модели с 2B параметров.
Mixture-of-Recursions: адаптивная глубина для каждого токена
И вот в последней работе Bae et al. (2025) делают следующий шаг. Они вводят механизмы маршрутизации, которые для каждого токена индивидуально решают, сколько раз применять рекурсивные блоки. Именно поэтому подход называется “смесью рекурсий”: небольшие подсети-маршрутизаторы делают обработку токенов адаптивной, динамически назначая различную глубину рекурсии отдельным токенам. Это значит, что если нужно породить простое функциональное слово, сеть сможет остановиться после первого прохода через рекурсивный блок, а для семантически богатого слова, которое нужно подумать, чтобы предсказать, сможет использовать, скажем, три итерации.
На иллюстрации ниже показаны (a) структура маршрутизатора, который может пропустить шаг рекурсии, (b) общая структура модели и (c) пример того, как более простые токены производятся меньшим числом шагов рекурсии, чем семантически богатые:
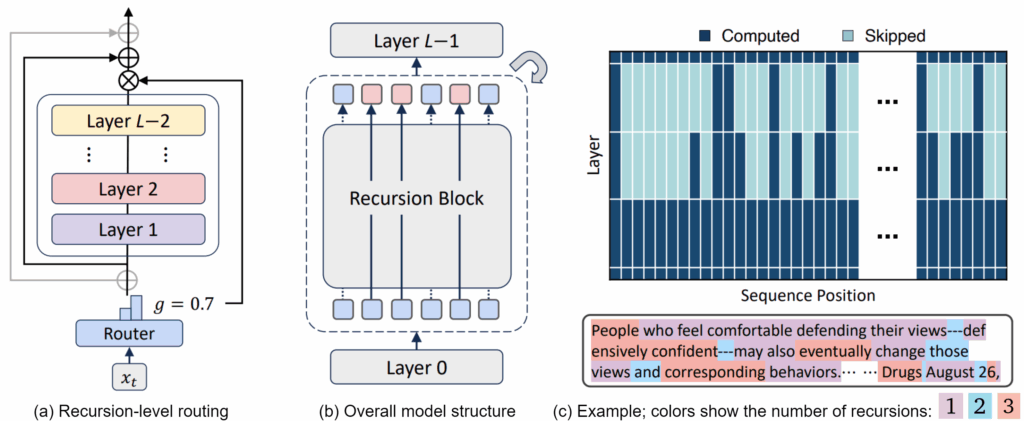
Идея в том, чтобы дать каждому токену ровно столько времени обработки, сколько ему нужно — ни больше, ни меньше. Сами роутеры обучаются во время обучения, развивая неявное понимание того, какие токены заслуживают более глубокой обработки.
Такую адаптивную маршрутизацию можно реализовать по-разному. Авторы сравнивают две стратегии:
- expert-choice routing (маршрутизация с выбором экспертом) рассматривает каждую глубину рекурсии как “эксперта” и выбирает, какие токены он хочет обработат; этот подход гарантирует идеальную балансировку нагрузки (большая проблема для MoE-моделей: как вы убедите роутер не отправлять всё на одного и того же эксперта?), поскольку здесь каждая итерация цикла обрабатывает фиксированное количество токенов; но тут нужно долго возиться с причинностью (в смысле causality), чтобы правильно получилось авторегрессивное порождение токенов;
- token-choice routing (маршрутизация с выбором токеном) идёт более простым путём: каждый токен заранее решает, сколько шагов рекурсии ему нужно; хотя это может привести к дисбалансу нагрузки (что если все токены захотят максимум?), авторы показывают, что эту проблему можно смягчить дополнительной регуляризацией (load balancing losses).
Вот иллюстрация двух схем маршрутизации от Bae et al. (2025):
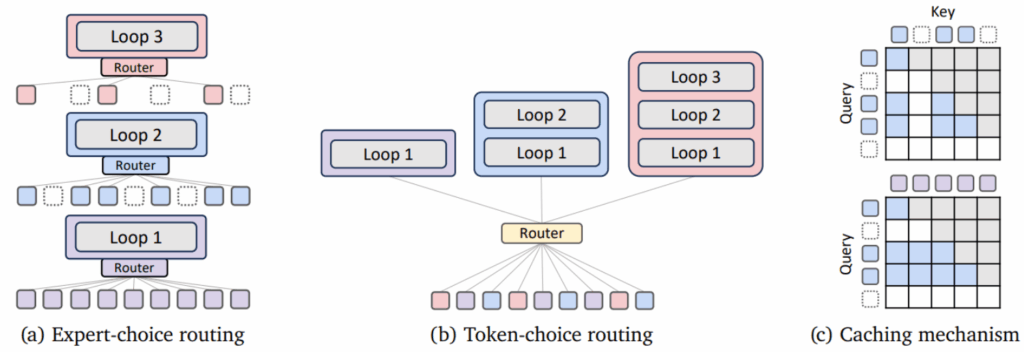
Кроме маршрутизации, эта картинка в части (с) иллюстрирует ещё и два механизма кэширования, которые в статье предложены:
- recursion-wise KV caching (рекурсивное KV-кэширование, сверху) сохраняет пары KV только для токенов, которые реально обрабатываются на каждой глубине рекурсии;
- recursive KV sharing (рекурсивное разделение KV, снизу) повторно использует пары KV, вычисленные на первом шаге рекурсии, для всех последующих шагов.
На практике оба подхода к маршрутизации дают хорошие результаты (expert-choice чуть получше), а кэширование нужно выбирать по необходимости: recursive KV sharing быстрее, но требует больше памяти, чем рекурсивное KV-кэширование.
Эмпирически у Bae et al. (2025) тоже всё неплохо получается: результаты демонстрируют, что MoR и теоретически элегантная идея, и практическую пользу приносит. При обучении с одинаковым вычислительным бюджетом MoR-модели стабильно превосходят обычные трансформеры, причём используя только около трети параметров эквивалентных стандартных моделей. Если дистиллировать Gemma 2B в рекурсивную Gemma 1B, получится модель гораздо лучше, чем если в обычную Gemma 1B, почти с такими же результатами, как исходная 2B.
Идея MoR также приводит к значительному ускорению инференса (до 2x) за счёт специального механизма continuous depth-wise batching: поскольку у вас многие токены уходят из обработки раньше других, освободившиеся места можно сразу же заполнять новыми токенами. Это тоже кажется важной идеей: получается, что состав батча всё время меняется, освободившаяся память не простаивает и обработка идёт максимально быстро.
Заключение
Mixture-of-Recursions представляется важной работой; скорее всего, это не последнее слово, но направление крутое. Пожалуй, главная критика, которая приходит на ум, состоит в том, что эксперименты пока очень маленькие: я упоминал Gemma 2B, и действительно это самая большая модель, с которой в статье есть эксперименты. Но всё-таки будет удивительно, если идея MoR вдруг перестанет работать при масштабировании.
Интересно, что MoR также естественным образом поддерживает test-time scaling: регулируя глубину рекурсии во время инференса, можно настраивать компромисс между качеством и скоростью. В некотором смысле MoR даёт естественный механизм для сложных рассуждений в латентном пространстве: раз токены могут проходить несколько раундов обработки, и это число раундов выбирает сам роутер, MoR-модель может обучиться “подумать, прежде чем говорить”.
В целом, мне кажется, что эта серия работ — Mixture-of-Depths, рекурсивные трансформеры, Mixture-of-Recursions — представляет собой очень перспективное направление. Получаются большие AI-модели, адаптивные не только в том, какие подсети они используют (как обычные MoE-модели), но и в том, сколько вычислений они используют.
Концептуально MoR представляет собой вертикальный вариант Mixture-of-Experts: вместо того чтобы распределять токены по широким экспертным матрицам, мы отправляем (или не отправляем) их дальше в глубину. Кстати, было бы очень легко объединить MoR и MoE, это естественный следующий шаг; думаю, тут это не сделано исключительно потому, что модели в целом пока что довольно маленькие. Я бы не удивился, если бы в скором времени в этом направлении появилась “3D-разреженная” модель — токены ⨉ глубина ⨉ эксперты.
Так что, как я всегда говорю, даже если физическое масштабирование так или иначе остановится (сложно уже транзисторы дальше уменьшать), алгоритмический прогресс принесёт нам ещё немало новостей и немало иксов улучшения эффективности (и по скорости, и по памяти). Будем следить за прогрессом!
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!