Hierarchical Reasoning Model: как 27М параметров решают судоку и ARC-AGI
8/21/2025

Современные LLM, даже рассуждающие, всё равно очень плохи в алгоритмических задачах. И вот, кажется, намечается прогресс: Hierarchical Reasoning Model (HRM), в которой друг с другом взаимодействуют две рекуррентные сети на двух уровнях, с жалкими 27 миллионами параметров обошла системы в тысячи раз больше на задачах, требующих глубокого логического мышления. Как у неё это получилось, и может ли это совершить новую мини-революцию в AI? Давайте разберёмся…
Судоку, LLM и теория сложности
Возможности современных LLM слегка парадоксальны: модели, которые пишут симфонии и объясняют квантовую хромодинамику, не могут решить судоку уровня «эксперт». На подобного рода алгоритмических головоломках точность даже лучших LLM в мире стремится к нулю.
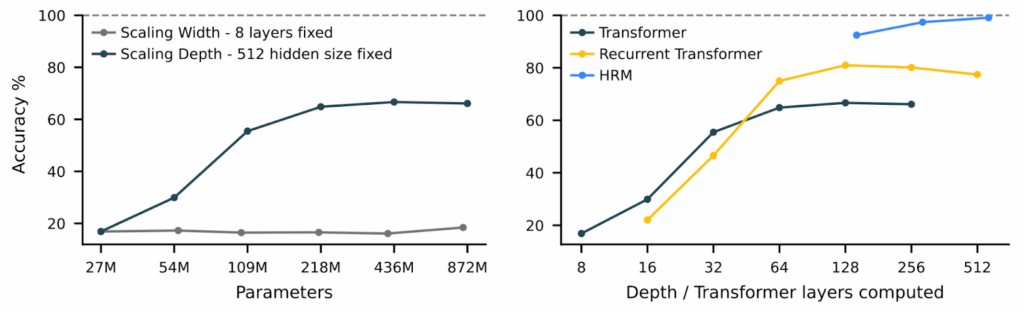
Это не баг, а фундаментальное ограничение архитектуры. Вспомните базовый курс алгоритмов (или менее базовый курс теории сложности, если у вас такой был): есть задачи класса P (решаемые за полиномиальное время), а есть задачи, решаемые схемами постоянной глубины (AC⁰). Трансформеры, при всей их мощи, застряли во втором классе, ведь у них фиксированная и не слишком большая глубина.
Представьте это так: вам дают лабиринт и просят найти выход. Это несложно, но есть нюанс: смотреть на лабиринт можно ровно три секунды, вне зависимости от того, это лабиринт 5×5 или 500×500. Именно так работают современные LLM — у них фиксированное число слоёв (обычно несколько десятков), через которые проходит информация. Миллиарды и триллионы параметров относятся к ширине обработки (числу весов в каждом слое), а не к глубине мышления (числу слоёв).
Да, начиная с семейства OpenAI o1 у нас есть “рассуждающие” модели, которые могут думать долго. Но это ведь на самом деле “костыль”: они порождают промежуточные токены, эмулируя цикл через текст. Честно говоря, подозреваю, что для самой LLM это как программировать на Brainfuck — технически возможно, но мучительно неэффективно. Представьте, например, что вам нужно решить судоку с такими ограничениями:
- смотреть на картинку можно две секунды,
- потом нужно записать обычными словами на русском языке то, что вы хотите запомнить,
- и потом вы уходите и возвращаетесь через пару дней (полностью “очистив контекст”), получая только свои предыдущие записи на естественном языке плюс ещё две секунды на анализ самой задачи.
Примерно так современные LLM должны решать алгоритмические задачи — так что кажется неудивительным, что они это очень плохо делают!
И вот Wang et al. (2025) предлагают архитектуру Hierarchical Reasoning Model (HRM), которая, кажется, умеет думать нужное время естественным образом:
Как работает HRM? Как бы избито и устарело это ни звучало, будем опять вдохновляться нейробиологией…
Тактовые частоты мозга и архитектура HRM
Нейробиологи давно знают, что разные области коры головного мозга работают на разных “тактовых частотах”. Зрительная кора обрабатывает информацию за миллисекунды, префронтальная кора “думает” секундами, а гиппокамп может удерживать паттерны минутами (Murray et al., 2014; Zeraati et al., 2023). Эти timescales измеряются обычно через временные автокорреляции между сигналами в мозге, результаты устойчивы для разных модальностей, и учёные давно изучают и откуда это берётся, и зачем это нужно (Zeraati et al., 2024):
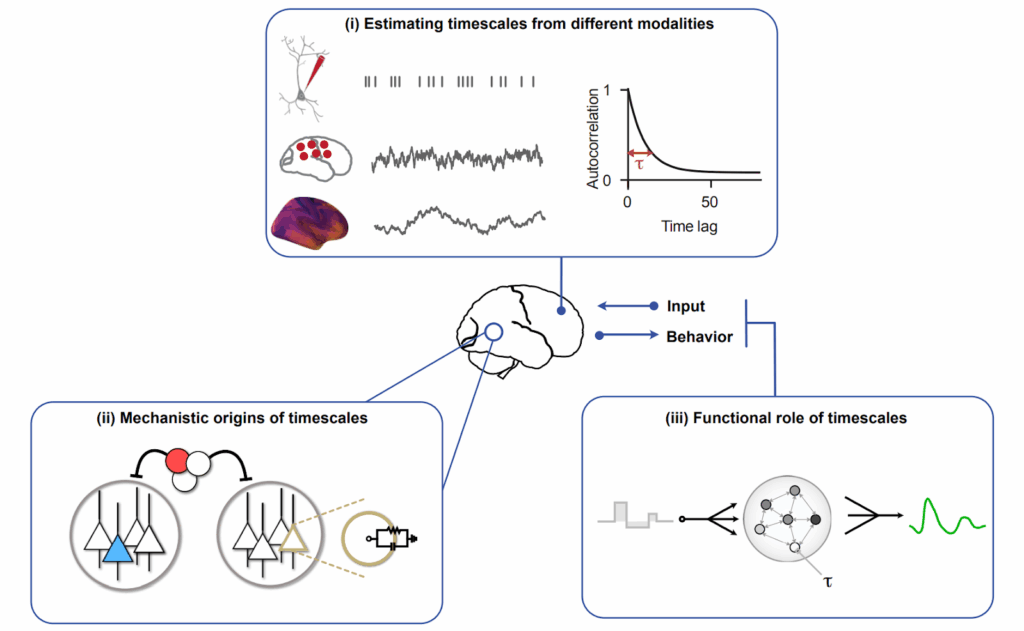
Это не случайность, а элегантное решение проблемы вычислительной сложности. Быстрые модули решают локальные подзадачи, медленные — координируют общую стратегию. Как дирижёр оркестра не играет каждую ноту, но задаёт темп и структуру всему произведению, а конкретные ноты играют отдельные музыканты.
Авторы Hierarchical Reasoning Model (HRM) взяли эту идею и применили её к рекуррентным сетям. Глубокие рекуррентные сети, у которых второй слой получает на вход скрытые состояния или выходы первого и так далее, конечно, давно известны, но что если создать рекуррентную архитектуру с двумя взаимодействующими уровнями рекуррентности? Верхний уровень будет получать результат нескольких шагов нижнего уровня, возможно уже после сходимости, и работать медленнее:
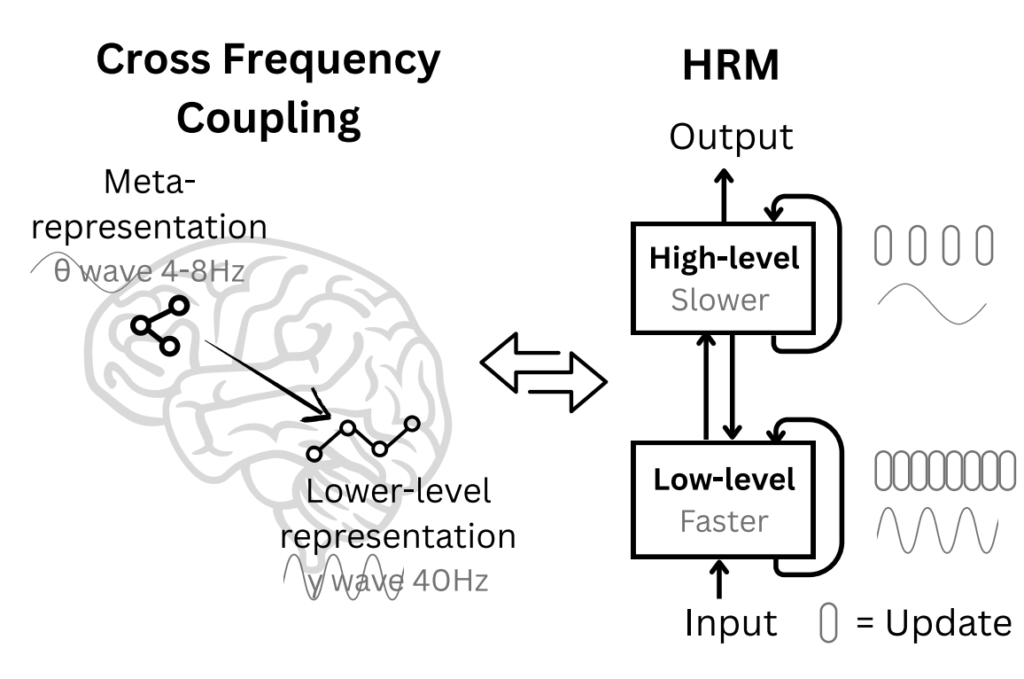
Идея настолько простая, что даже удивительно, почему её не попробовали раньше (а может, уже пробовали?). По сути, мы просто обучаем две вложенные рекуррентные сети:
- быстрый модуль (L) выполняет T шагов вычислений, сходясь к локальному решению;
- медленный модуль (H) обновляется раз в T шагов, меняя тем самым контекст для быстрого модуля.
Но дьявол, как всегда, в деталях. Просто соединить две RNN-архитектуры недостаточно — они или быстро сойдутся к фиксированной точке и перестанут что-либо вычислять, или будут требовать огромных ресурсов для обучения. Нужны ещё трюки, и в HRM они довольно простые, так что давайте их тоже рассмотрим.
Важные трюки
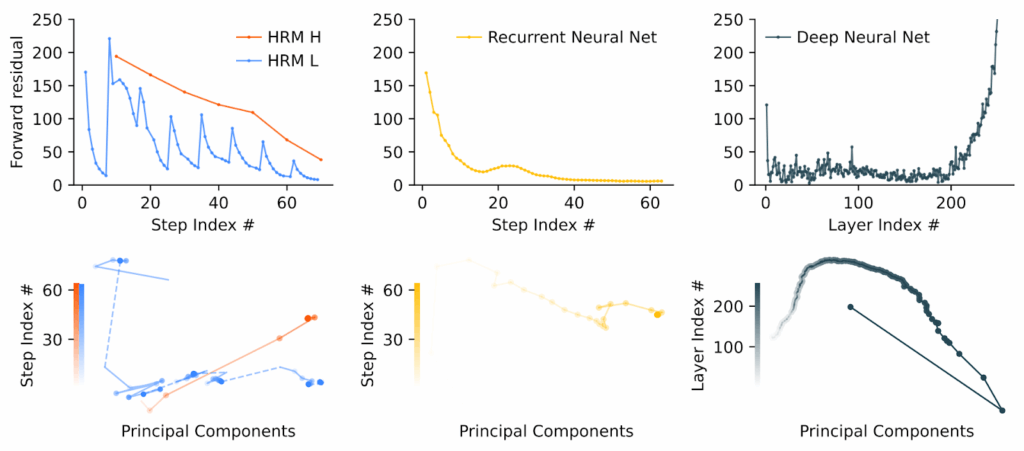
Трюк №1: Иерархическая сходимость
Вместо одной большой задачи оптимизации HRM решает последовательность связанных задач. Быстрый модуль сходится, потом медленный модуль обновляется, и появляется новая точка сходимости для быстрого модуля. Для быстрого модуля всё выглядит как решение последовательности связанных, но всё-таки разных задач, и ему всё время есть куда двигаться. Это хорошо видно на графиках сходимости:
Трюк №2: Backpropagation, But Not Through Time
Обычно рекуррентные сети обучаются при помощи так называемого backpropagation through time (BPTT): нужно запомнить все промежуточные состояния, а потом распространить градиенты назад во времени. Хотя это вполне естественно для обучения нейросети, это требует много памяти и вычислительных ресурсов, а также, честно говоря, биологически неправдоподобно: мозг же не хранит полную историю всех активаций своих синапсов, у мозга есть только текущее состояние.
HRM использует идеи из Deep Equilibrium Models и implicit models — градиенты вычисляются только по финальным сошедшимся состояниям:
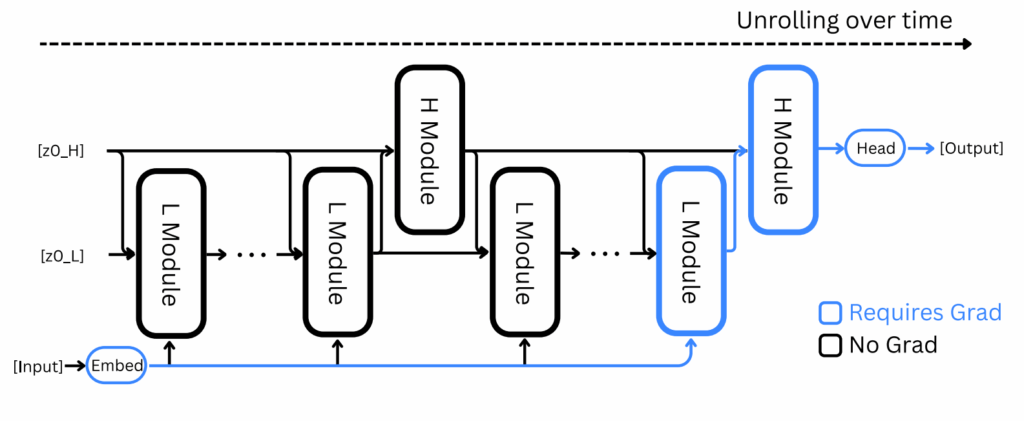
Получается, что хранить нужно только текущие состояния сетей; O(1) памяти вместо O(T)! Конечно, это не то чтобы сложная идея, и при обучении обычных RNN у неё есть очевидные недостатки, но в этом иерархическом случае, похоже, работает неплохо.
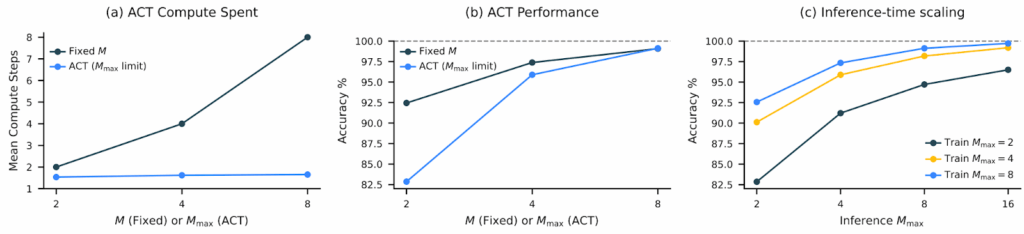
Трюк №3: Адаптивное мышление через Q-learning
Не все задачи одинаково сложны. HRM может “думать дольше” над трудными проблемами, используя механизм адаптивной остановки, обученный через reinforcement learning. Если судоку на 80% заполнено, то скорее всего хватит и пары итераций, а в начале пути придётся крутить шестерёнки иерархических сетей подольше. Это тоже не новая идея — Alex Graves ещё в 2016 предлагал adaptive computation time for RNNs — но в этом изводе результаты действительно впечатляющие, всё хорошо обучается и работает:
Результаты
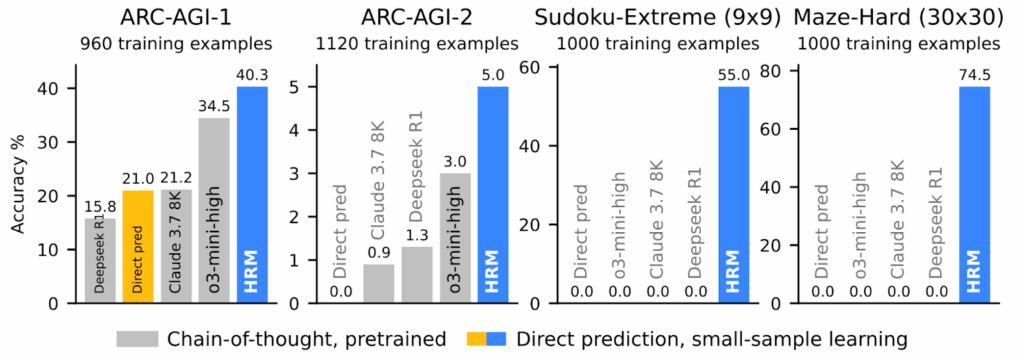
Экспериментальные результаты тут, конечно, крайне впечатляющие. Можно сказать, переворачивают представление о том, что такое “эффективность” в AI. Всего с 27 миллионами параметров, обучаясь примерно на 1000 примеров, HRM получила:
- 40.3% на ARC-AGI-1 (тест на абстрактное мышление, где o3-mini даёт 34.5%, а Claude — 21.2%);
- 55% точных решений для экстремально сложных судоку (здесь рассуждающие модели выдают устойчивый ноль решений);
- 74.5% оптимальных путей в лабиринтах 30×30 (где, опять же, рассуждающие модели не делают ничего разумного).
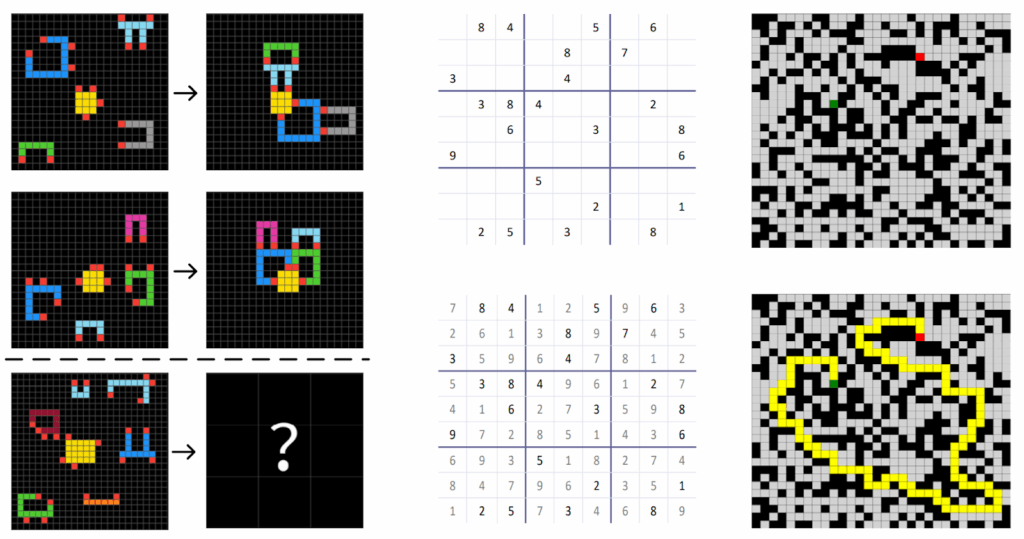
Для контекста скажу, что задачи действительно сложные; например, судоку в тестовом наборе требуют в среднем 22 отката (backtracking) при решении алгоритмическими методами, так что это не головоломки для ленивого заполнения в электричке, а сложные примеры, созданные, чтобы тестировать алгоритмы. Вот, слева направо, примеры заданий из ARC-AGI, судоку и лабиринтов:
Заглядываем под капот: как оно думает?
В отличие от больших моделей, у которых интерпретируемость потихоньку развивается, но пока оставляет желать лучшего, HRM позволяет наглядно визуализировать процесс мышления:
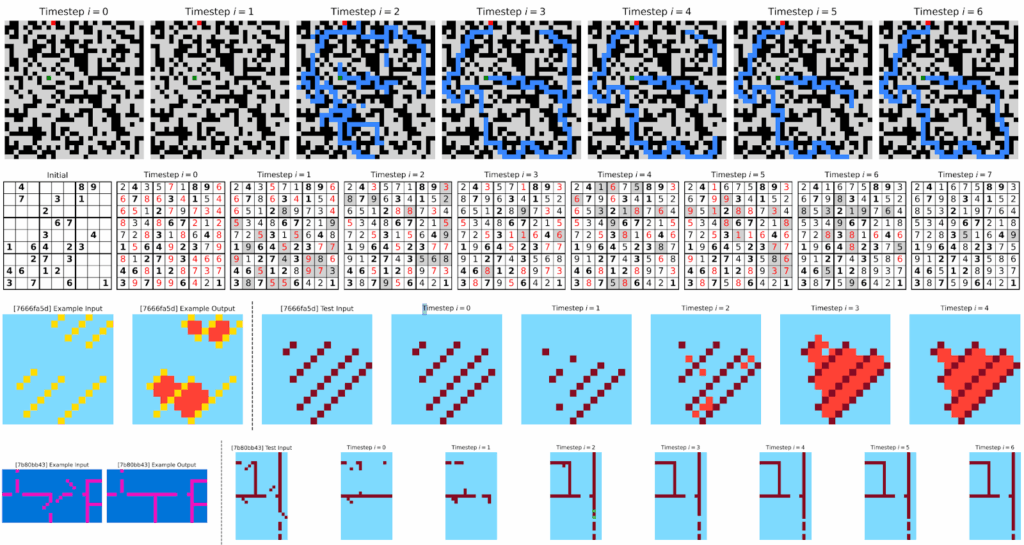
Здесь хорошо видно, что:
- в лабиринтах HRM сначала исследует множество путей параллельно, потом отсекает тупики;
- в судоку получается классический поиск в глубину — заполняет клетки, находит противоречия, откатывается;
- а в ARC-задачах всё это больше похоже на градиентный спуск в пространстве решений.
Спонтанная иерархия размерностей
Я начал этот пост с аналогии с мозгом. Они часто в нашей науке появляются, но обычно не имеют особенно глубокого смысла: в мозге нет backpropagation, как следствие там совсем другая структура графа вычислений, и аналогии редко выдерживают этот переход. Но в данном здесь параллель оказалась глубже, чем даже изначально предполагали авторы. После обучения в HRM сама собой развивается “иерархия размерностей” — высокоуровневый модуль работает в пространстве примерно в 3 раза большей размерности, чем низкоуровневый (центральный и правый столбцы):
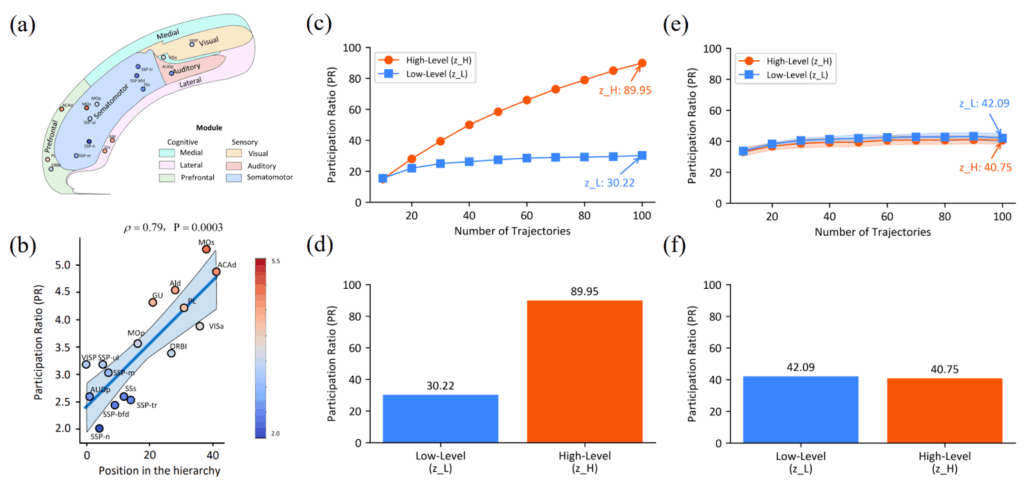
И оказывается, то точно такая же организация наблюдается в мозге мыши (Posani et al., 2025; левый столбец на картинке выше)!
Этот эффект не был задан через гиперпараметры, а возник сам собой, эмерджентно из необходимости решать сложные задачи. Тут, конечно, результат не настолько мощный, чтобы рассуждать о каком-то фундаментальном принципе организации иерархических вычислений, который независимо открывают и биологическая эволюция, и градиентный спуск… но вот я уже порассуждал, и звучит довольно правдоподобно, честно говоря.
Заключение: ограничения и философствования
Во-первых, давайте всё-таки не забывать важные ограничения HRM:
- все тесты были сделаны на структурированных задачах (судоку, лабиринты), а не на естественном языке;
- результаты на ARC сильно зависят от test-time augmentation (1000 вариантов каждой задачи);
- для идеального решения судоку нужны все 3.8M обучающих примеров, а не заявленные 1000.
И главный вопрос, на который пока нет ответа: масштабируется ли это до размеров современных LLM? Если да, то это может быть важный прорыв, но пока, конечно, ответа на этот вопрос мы не знаем.
И тем не менее, HRM побуждает слегка переосмыслить, что мы называем мышлением в контексте AI. Современные LLM — это всё-таки по сути своей огромные ассоциативные машины. Они обучают паттерны из триллионов токенов данных, а потом применяют их, с очень впечатляющими результатами, разумеется. Но попытки рассуждать в глубину пока всё-таки достигаются скорее костылями вроде скрытого блокнотика для записей, а по своей структуре модели остаются неглубокими.
HRM показывает качественно иной подход — алгоритмическое рассуждение, возникающее из иерархической архитектуры сети. HRM может естественным образом получить итеративные уточнения, возвраты и иерархическую декомпозицию. Так что, возможно, это первая ласточка того, как AI-модели могут разделиться на два класса:
- ассоциативный AI вроде LLM: огромный, прожорливый к данным и предназначенный для работы с естественным языком и “мягкими” задачами;
- алгоритмический AI вроде HRM: компактный, не требующий больших датасетов и специализированный на конкретных задачах, для которых нужно придумывать и применять достаточно сложные алгоритмы.
Разумеется, эти подходы не исключают друг друга. Вполне естественно, что у гибридной модели будет LLM для понимания контекста и порождения ответов, которая будет как-то взаимодействовать с HRM или подобной моделью, реализующей ядро логических рассуждений. Как знать, может быть, через несколько месяцев такими и будут лучшие нейросети в мире…
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!