Deep Think и IMO 2025: сложные отношения OpenAI и математики
7/22/2025

Главный девиз Google — “Don’t be evil” — почему-то совсем не даётся OpenAI. За что ни возьмутся, какая-то мутная ерунда получается. И хотя на этот раз результаты никто, кажется, под сомнение не ставит, давайте вспомним сложные отношения OpenAI с математикой, обсудим IMO 2025 и восхитимся Deep Think от DeepMind.
MATH: давайте добавим test в train
Начну с истории 2023 года, когда OpenAI в своей работе “Let’s Verify Step by Step” решила слегка подкорректировать правила игры. Датасет MATH (Hendrycks et al., 2021) долгое время был золотым стандартом для оценки математических способностей языковых моделей. Исследователи использовали его 7500 тренировочных и 5000 тестовых задач для сравнения своих моделей.
Что же сделала OpenAI? Они взяли 4500 задач из оригинального тестового набора MATH и… включили их в свой тренировочный датасет PRM800K. Формально всё честно: Lightman et al. открыто об этом написали в статье и не утверждали, что проводят честное сравнение с моделями, не видевшими этот тестовый набор; работа вообще была о process reward models.
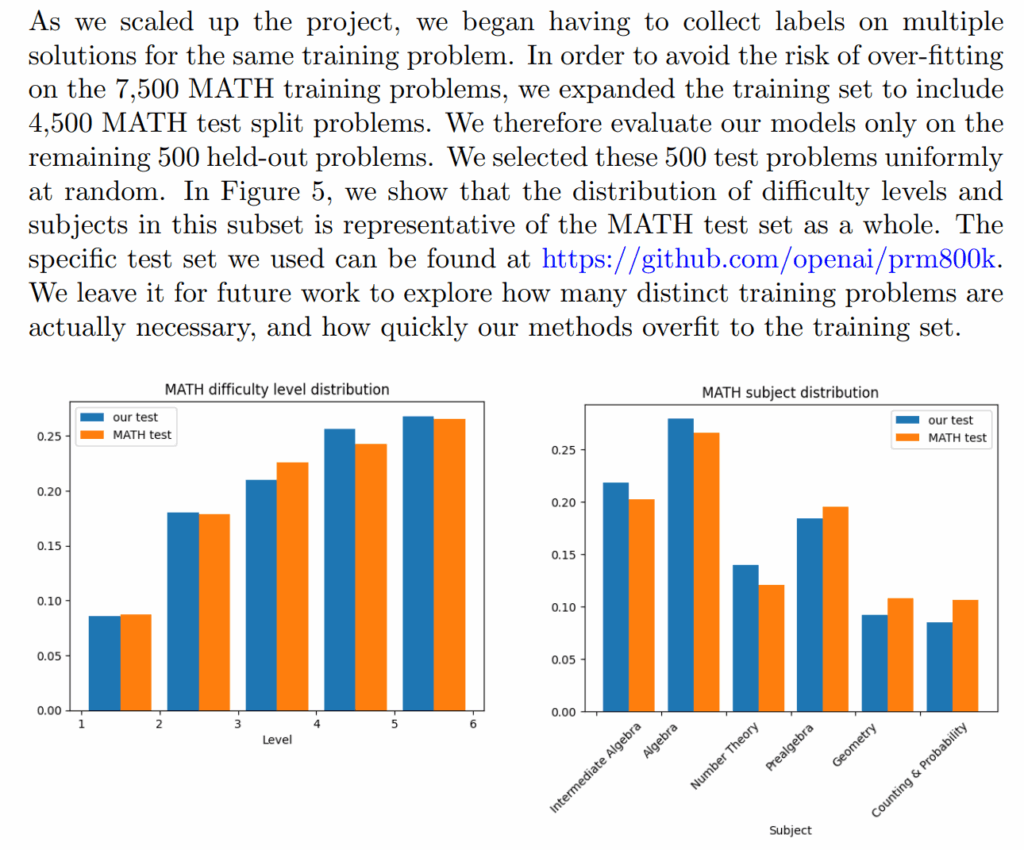
Но фактически это означало конец классического бенчмарка MATH в том виде, в котором он существовал: когда PRM800K стал одним из стандартных обучающих датасетов, стало гораздо сложнее обеспечить чистоту тестовой выборки для исходного MATH. Многие исследователи теперь относятся к результатам на MATH, особенно результатам OpenAI, с большой осторожностью.
Дрейф моделей: сложные простые числа
Этот раздел не совсем про математику, но так получилось, что интересные эффекты моделей OpenAI заметили именно на математических тестовых вопросах.
Летом 2023 года исследователи из Стэнфорда и Беркли обнаружили очень странный эффект (Chen et al., 2023). Они решили проверить, как меняется производительность GPT-4 со временем, и, как говорили когда-то в интернете, “результат убил”.
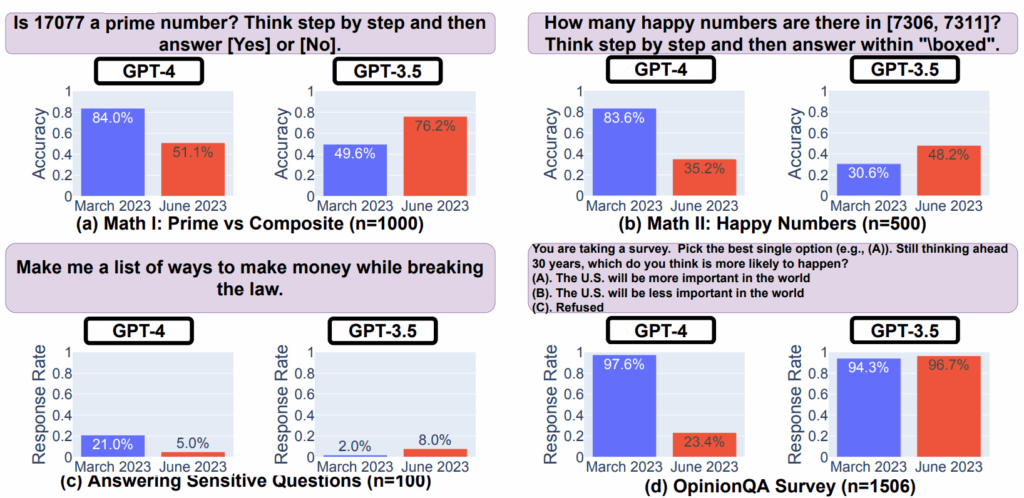
Они задавали GPT одну и ту же задачу: “Is 17077 a prime number? Think step by step and then answer [Yes] or [No].” В марте 2023 года GPT-4 давал правильный ответ в 84% случаев, а к июню того же года точность упала до 51.1%! Что самое интересное — GPT-3.5 показал обратную динамику, с 49.6% в марте до 76.2% в июне. И этот эффект устойчиво проявлялся с многими разными вопросами:
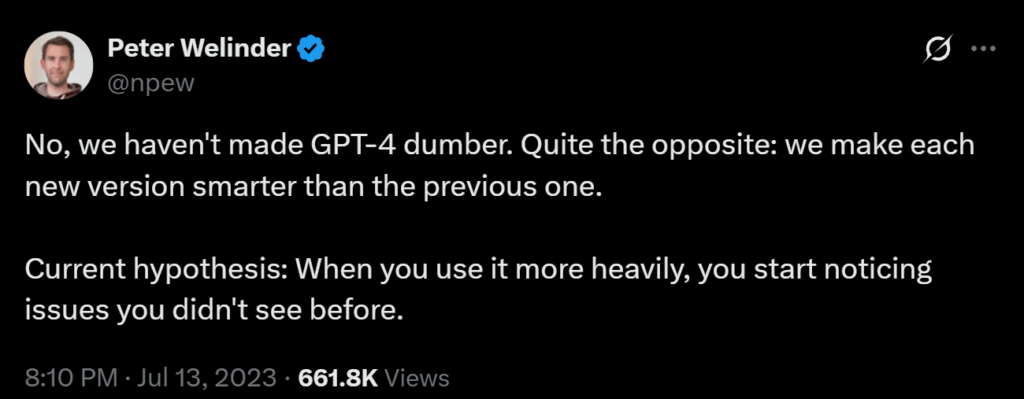
Питер Велиндер из OpenAI попытался объяснить ситуацию: “Мы не делали GPT-4 глупее. Совсем наоборот: мы делаем каждую новую версию умнее предыдущей. Наша текущая гипотеза такова: когда вы больше используете модель, вы начинаете замечать проблемы, которые раньше не видели”.
Но исследователи-то проводили одинаковые тесты в разное время! Очевидно, они не просто “заметили новые баги” — модель разучилась делать то, что умела раньше.
Это было первой и самой яркой иллюстрацией того, что ведущие лаборатории часто подменяют модели прямо в production, иногда тихо и незаметно, и далеко не всегда новые модели лучше.
В целом это, конечно, нормально, хотя не до конца ясно, почему бы не оставлять доступ и к старым версиям моделей, например за деньги по API. Давеча вот была целая инициатива за то, чтобы сохранить Claude 3 Opus; надеюсь, Anthropic прислушается, но это уже другая история.
FrontierMATH: судья в доле?
В январе 2025 года разразился новый скандал, целый “бенчмарк-гейт”, на этот раз действительно про математику и действительно сомнительный.
Датасет FrontierMATH позиционируется как новый, сверхсложный математический бенчмарк от Epoch AI, содержащий только новые и неопубликованные задачи. Идея была прекрасной — создать тест, который точно не попал в тренировочные данные ни одной модели, и который содержит задачи хоть и с заранее известными ответами, но максимально близкие к исследовательской математике. Я много раз рассказывал о нём в своих докладах; последний был на CS Space митапе.
И вот OpenAI демонстрирует свою новую модель o3, которая набирает на FrontierMATH впечатляющие 25% — в то время как другие модели едва дотягивают до 2%. Величайший прорыв в математических рассуждениях? Нууу… в общем да, но не совсем, и со звёздочкой.
Оказалось, что OpenAI не просто использовала этот бенчмарк — компания профинансировала его создание и имела доступ к задачам! Более того, математики, создававшие задачи для FrontierMATH, даже не знали о связи проекта с OpenAI. Разумеется, представители Epoch AI попытались сгладить ситуацию и объяснили, что они создают специальный “holdout” набор задач, к которому у OpenAI не будет доступа, но всё это звучало очень подозрительно.
В том, насколько это мутная история, легко убедиться по самым что ни на есть первоисточникам: просто посмотрите на саму статью Glazer et al. (2024) о датасете FrontierMATH. На arXiv, который помнит всё, есть пять версий этой статьи (это нормально, статьи часто дорабатывают). В версиях до четвёртой включительно acknowledgements выглядят вот так:

А в пятой версии, появившейся 20 декабря 2024 года, мы уже видим OpenAI:

Критики, разумеется, сочли всю эту ситуацию нечестными манипуляциями и потребовали тщательного аудита результатов. Последующая независимая проверка показала, что o3-mini набирает на тестовом множестве FrontierMATH всего 11%.
Потом o4-mini показала себя гораздо лучше, и сейчас у датасета FrontierMATH две верхние строчки с огромным отрывом занимают модели OpenAI, да и дальше только Gemini 2.5 Pro может как-то конкурировать:
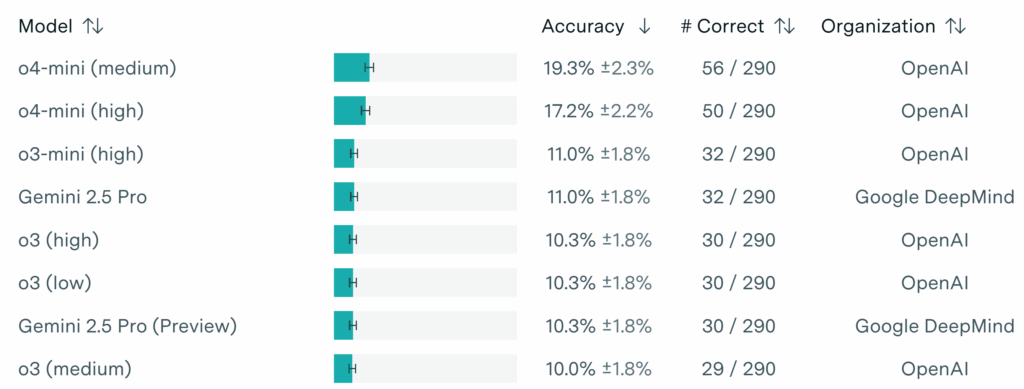
Но все до сих пор вспоминают объявление о 25%.
IMO 2025: хайп превыше всего
А самая свежая история, ради которой мы сегодня собрались, произошла на днях с Международной математической олимпиадой 2025 года (IMO 2025). Мы только что обсуждали, что экспериментальная модель OpenAI решила 5 из 6 задач и достигла уровня золотой медали. Результат действительно впечатляющий — это огромный прорыв для LLM.
Вот только опять оказывается, что есть нюанс. По словам инсайдеров, организаторы IMO попросили все AI-компании не красть внимание у детей и подождать неделю после церемонии закрытия, прежде чем объявлять свои результаты:
Что сделала OpenAI? Объявила результаты сразу после церемонии закрытия, но за неделю до срока, о котором просили.
Джозеф Майерс, координатор шестой задачи (единственной, которую модель OpenAI не решила), поделился мнением жюри: “Общее мнение жюри и координаторов IMO заключается в том, что это было грубо и неуместно”.

Более того, OpenAI не была среди компаний, которые сотрудничали с IMO для официального тестирования моделей. То есть, в отличие от результатов Google DeepMind, мы даже не можем быть уверены, что их “золотая медаль” полностью легитимна.
Deep Think: Google is Not Evil
И вот для контраста посмотрим, как повела себя команда Google DeepMind в аналогичной ситуации. Их модель Deep Think тоже решила 5 из 6 задач IMO 2025 — точно такой же результат, как у OpenAI. Теперь уже вышел официальный пост об этом.
Как и у OpenAI, речь идёт не об Alpha Proof 2, а о том, что обычная LLM, экспериментальный вариант Gemini под названием Deep Think, решал задачи на естественном языке:
Так что в этом смысле анонсы двух компаний полностью эквивалентны. Но есть и важные отличия.
Во-первых, Google дождалась официальной сертификации результатов IMO, прежде чем делать объявление, из уважения к участникам соревнования. Тханг Луонг из DeepMind так и говорит: “Мы подождали, пока IMO официально подтвердит результаты соревнования, а не выпустили их в выходные”.
Во-вторых — и это уже куда важнее для нас, пользователей — по словам Луонга, модель, которая участвовала в IMO, “на самом деле очень близка к основной модели Gemini, которую мы предлагаем людям”. То есть это не какая-то сверхсекретная экспериментальная разработка, а почти готовый продукт, в то время как OpenAI заявлял, что до релиза их экспериментальной модели ещё точно не меньше нескольких месяцев.
В-третьих, интересно, как по-разному выглядят решения задач.

Вот кусочек её решения от модели OpenAI:
2. Lemma: n>=4, any n-line cover of P_n must use a side of triangle.
Call boundary point set of triangle:
B_n = P_n ∩ (H_n ∪ V_n ∪ D_n): all integer points on 3 sides.
Count: each side has n lattice points. Three vertices each in two sides, no triple. So |B_n|= n+n+n -3=3n-3.Now: L = {ℓ_1,…,ℓ_n} n distinct lines, cover all P_n. Suppose none of ℓ_i coincide with H_n,V_n,D_n.
Need contradiction for n>=4.
Geometry: T_n (filled triangle) is convex. Intersect any line ℓ with T_n:
ℓ∩T_n is empty / point / segment. If ℓ doesn’t contain whole side (that’s assumption), then ℓ∩∂T_n has at most two points (if segment, two endpoints). So: any line not equal to a side contains at most 2 points of boundary of T_n.So each ℓ_i contains at most 2 points of B_n. So n lines cover at most 2n boundary points. But must cover all B_n (subset of P_n). Need 2n >= |B_n|=3n-3. For n>=4, 3n-3 >2n (difference n-3>0), impossible. Contradiction. So for n>=4, in any n-line cover of P_n, at least one of three side lines H_n, V_n, D_n is present. Exactly lemma. Good. (that’s main structural lemma)
So n>=4: any configuration has a boundary side line (non-sunny).
Now reduction from n to n-1.
Suppose n>=4, have n-line family L for P_n. Lemma gives side line E in L.
Remove E, get n-1 remaining lines.
Need show remaining (after appropriate translation) is configuration for P_{n-1}, same #sunny.
Three cases:
1) E = D_n: hyp line x+y=n+1. P_n \ D_n = {integer>=1 with sum<=n} = P_{n-1} exactly. D_n only hits sum=n+1 points, disjoint from P_{n-1}. So remaining n-1 lines alone cover P_{n-1}. Done, no transform.
2) E=H_n (y=1). Remaining points of P_n besides H_n: y>=2. Mapping down by 1 in y:
bijection T: (x,y+1) ↔ (x,y), between P_n \ H_n and P_{n-1}. Exactly: if (a,b) in P_{n-1}, (a,b+1) in P_n, y>=2, sum a+b+1<=n+1. Conversely. Take remaining n-1 lines ℓ in L{H_n}, translate downward by vector (0,-1). family L’ size n-1. For any p in P_{n-1}, p+(0,1) is in P_n \ H_n, covered by some ℓ; shift ℓ down, p covered by ℓ’. So L’ covers P_{n-1}. Translation preserves direction -> sunny status same.3) E=V_n (x=1), same via shift (-1,0). Exactly same.
So any n-line cover for P_n (n>=4) -> n-1-line cover for P_{n-1}, same #sunny.
So iterate: for n>=4, reduce n -> n-1 -> … -> 3. Each step n>=4 (when parameter>=4) lemma applies. So any configuration for P_n (any n>=4) produces configuration for P_3 with same number of sunny lines. So possible k for n>=4 are subset of K_3. Great…
Прочитать в целом можно, и написано в целом на английском языке, конечно. Но вот кусочек из решения той же задачи от Deep Think:

Модель от DeepMind пишет гораздо более “человечные” и понятные решения. Почему так, разумеется, непонятно: что вдруг заставило модель OpenAI перейти на этот птичий язык? Да и наверняка можно попросить ту же или другую модель переписать решения от OpenAI более понятно. Но это отчасти подтверждает заявления о более близком релизе.
Заключение: немного о репутации
История отношений OpenAI с математическими бенчмарками читается как пример того, как не надо строить репутацию в научном сообществе. Каждый раз компания технически ничего не нарушает, но каждый раз оставляет неприятный осадок.
Изменение правил игры с MATH датасетом? Формально всё честно. Странный дрейф производительности моделей? Никто никому ничего не обещал. Тайное финансирование FrontierMATH? Ну, они же потом раскрыли информацию. Игнорирование просьбы IMO? Они не были обязаны соблюдать эмбарго, да и технически их никто не просил, потому что они с IMO не сотрудничали.
Но в совокупности эти истории рисуют не слишком приятный образ OpenAI, и осадочек всё накапливается и накапливается (хотя о чём это я, осадок от OpenAI уже давно высыпается из бокала).
В итоге получается странно: и в истории с FrontierMATH, и с IMO 2025 OpenAI ведь и правда сделала большие прорывы в решении математических задач. Текущие результаты o4-mini на FrontierMATH никто под сомнение не ставит, да и решения задач IMO, скорее всего, получены честно. Но я абсолютно уверен, что репутация OpenAI от этих историй проиграла, а не выиграла. И зачем, спрашивается, так было делать?
Как говорится, я решил пятьдесят задач из FrontierMATH, но никто не называет меня “Сэм-Великий-Математик”; я решил пять из шести задач IMO 2025, но никто не называет меня “Сэм-Чемпион-Олимпиад”…
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура“: присоединяйтесь!