“А теперь побей все бенчмарки”: AI-ассистент для учёных на основе MCTS
9/10/2025

Я в своих докладах люблю пугать людей тем, что AI уже потихоньку начинает самостоятельно проводить исследования. Рассказывал вам уже про Google Co-Scientist, AI Scientist от Sakana AI, Robin, Zochi… Там были и важные новые идеи, и даже полностью автоматически порождённые статьи, принятые сначала на workshop при ICLR, а потом и на главную конференцию ACL. И вот вчера вышла ещё одна новость в том же направлении, на этот раз от Deepmind (и других подразделений Google Research). Кажется, AI-системы сделали ещё один шаг вверх по лестнице абстракций…
Введение
Представьте себе, что вы — учёный-биоинформатик, и вам нужно интегрировать данные секвенирования РНК отдельных клеток (single-cell RNA-seq) из десятка разных лабораторий. У каждой лаборатории был свой протокол, свои секвенаторы (по крайней мере, разные настройки секвенаторов), свои реагенты и свои условия эксперимента (насколько я понимаю, там даже влажность в лаборатории может повлиять на результат).
Теперь у вас есть тысячи разных датасетов с разными так называемыми batch effects (грубо говоря, шум, специфичный для этого датасета). И если вы возьмёте одинаковые T-клетки, измеренные в Гарварде и в Стэнфорде, любой наивный метод сравнения скажет, что это совершенно разные типы клеток — не потому что они правда разные, а потому что технические различия затмевают биологические.
Вы должны написать код, который должен их убрать, сохранив при этом биологический сигнал. Это как если бы вам нужно было взять сто фотографий леса с разных камер при разной погоде и в разной освещённости и привести их к единому стилю, то есть убрать различия камер, но обязательно сохранить то, что на одних фотографиях — лето, на других — осень, а на третьей пробежал зайчик.
Эта задача называется batch integration: как объединить разные single-cell датасеты, сохранив биологический сигнал. Задача очень важная и для Human Cell Atlas, который картирует все типы клеток в организме, и для онкологических исследований, и для, например, анализа того, как COVID-19 повлиял на иммунитет. Про неё есть датасеты, бенчмарки и лидерборды (Шишков, прости!), которые проверяют много разработанных исследователями метрик качества batch integration.
И вот вы садитесь делать batch integration. Через неделю у вас есть рабочий пайплайн. Он… ну, работает. Вроде бы. На ваших данных. Может быть. Точнее, в соответствии со знаменитым xkcd, у вас есть триста первый вроде бы рабочий пайплайн, потому что ещё в 2018-м их было около трёхсот (Zappia et al., 2018).
А теперь представьте, что AI-система берёт те же датасеты, порождает несколько десятков различных подходов, тестирует их все на публичном бенчмарке и выдаёт вам 40 методов, которые превосходят текущих лидеров человеческого лидерборда. И всё это за несколько часов вычислительного времени.
Фантастика? Кажется, что уже реальность, данная нам в ощущениях в только что вышедшей статье от Google Deepmind (и других отделах Google Research): Aygün et al., “An AI system to help scientists write expert-level empirical software”, выложена на arXiv 8 сентября 2025 года.
Но самое интересное, как водится, не в цифрах, а в том, как эта система работает. Это не просто “LLM пишет код”, а скорее продолжение семейства AI-систем от DeepMind, которые дали нам AlphaTensor, FunSearch и AlphaEvolve. В данном случае это сочетание трёх ингредиентов: поиска по дереву (как в AlphaGo), добавления идей из научной литературы (через LLM) и, самое интересное, рекомбинации методов (как в генетическом программировании), когда система скрещивает два алгоритма и получает гибрид, который может работать лучше обоих родителей.
Давайте разберёмся подробнее…
Код как пространство для поиска
Если вы следили за развитием всевозможных “ИИ-учёных” в последние пару лет, то видели уже много попыток автоматизировать процесс научного открытия. Был FunSearch от DeepMind, который использовал эволюционный поиск программ для перебора случаев в математических задачах. Есть AI Scientist от Sakana AI, который порождает целые научные статьи end-to-end. Недавно появился Google Co-Scientist, который предлагает идеи и планирует эксперименты на естественном языке. А последние версии AI Scientist и Robin уже написали полностью автоматически порождённые статьи, принятые сначала на workshop при ICLR, а потом и на главную конференцию ACL. Об этом всём я уже рассказывал в блоге:
Но все эти системы до сих пор объединяло то, что они работали в пространстве идей и текста: придумать через LLM что-то новенькое, через LLM же запрограммировать, посмотреть на результаты и опять попробовать что-то новенькое.
А система Aygün et al. (2025) работает в пространстве исполняемого кода с численной метрикой качества. Иначе говоря, вместо того чтобы писать красивые описания методов на английском языке, она работает в таком цикле:
- берёт работающий код (начиная с какого-то существующего baseline, разумеется)
- переписывает его с помощью LLM, внося некоторые изменения
- запускает и получает численную оценку (score на конкретном бенчмарке)
- использует поиск по дереву для систематического исследования пространства возможных модификаций.
Вот иллюстрация из статьи:
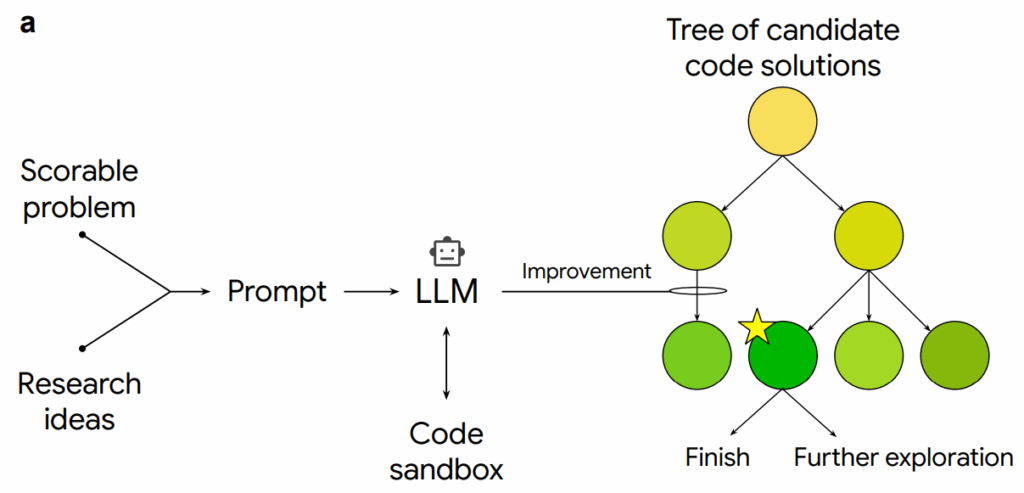
По сути, это превращает задачу “придумай новый научный метод” в задачу “найди путь в дереве кодовых мутаций, который максимизирует score”. И оказывается, что последняя может оказаться для современных AI-систем существенно проще.
Что за поиск по дереву?
Здесь стоит остановиться подробнее. Вы наверняка помните, как AlphaZero использовал Monte Carlo Tree Search (MCTS) для игры в го и шахматы:
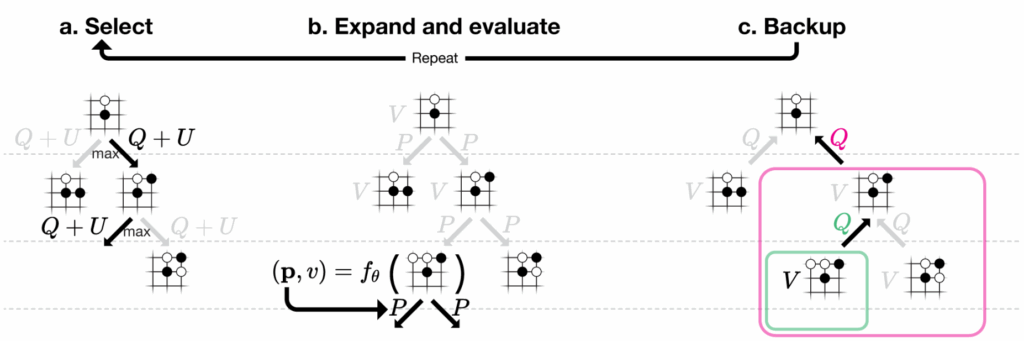
MCTS — это хорошее решение стандартной задачи обучения с подкреплением: как найти правильный баланс между
- использованием (exploitation) веток, которые уже показали хороший результат, и
- исследованием (exploration) новых веток дерева.
Всё это на самом деле довольно базовые вещи в RL, по сути небольшое расширение идеи UCB-алгоритмов на деревья. В последний раз я рассказывал об MCTS весной, в курсе на МКН СПбГУ; вот лекция, где мы разговариваем о том, как устроен RL в AlphaZero.
Точно так же работает и эта система. Она не просто абстрактно думает, “что бы ещё улучшить”, а строит дерево, где каждый узел представляет собой версию программы, а рёбра — конкретные модификации. Если какая-то модификация улучшила оценку, система с большей вероятностью будет исследовать эту ветку дальше. Главное здесь в том, чтобы была конкретная численная оценка, которую мы оптимизируем, аналог вероятности победы в го; ну и ещё, конечно, чтобы ставить новый эксперимент было не слишком дорого, т.е. чтобы мы могли позволить себе построение этого дерева.
И в отличие от го, где правила фиксированы, здесь система может делать любые изменения кода: менять архитектуру модели, добавлять шаги предобработки, переписывать функции ошибки, комбинировать методы… Пространство поиска огромно, но MCTS позволяет эффективно в нём искать.
В результате может получиться дерево вроде вот такого:
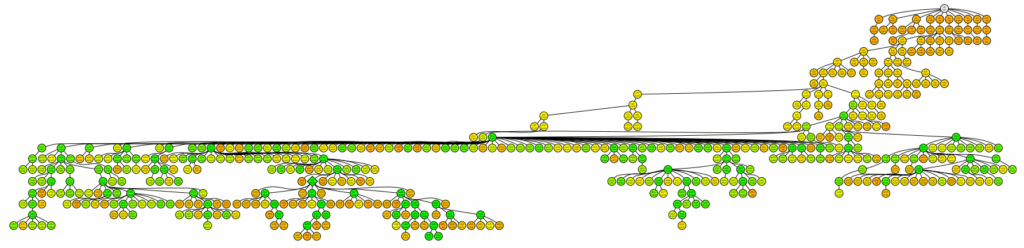
Многорукие бандиты из MCTS здесь делают поиск более направленным; обратите внимание, что дерево вовсе не такое уж широкое, и в нём есть конкретные узлы с “хорошими идеями”, которые начинают постоянно использоваться и перетягивать на себя поиск. Эти “хорошие идеи” скорее всего соответствуют скачкам в целевой функции, и причины этих скачков вполне можно постичь человеческим разумом, это же просто изменения в коде экспериментов:
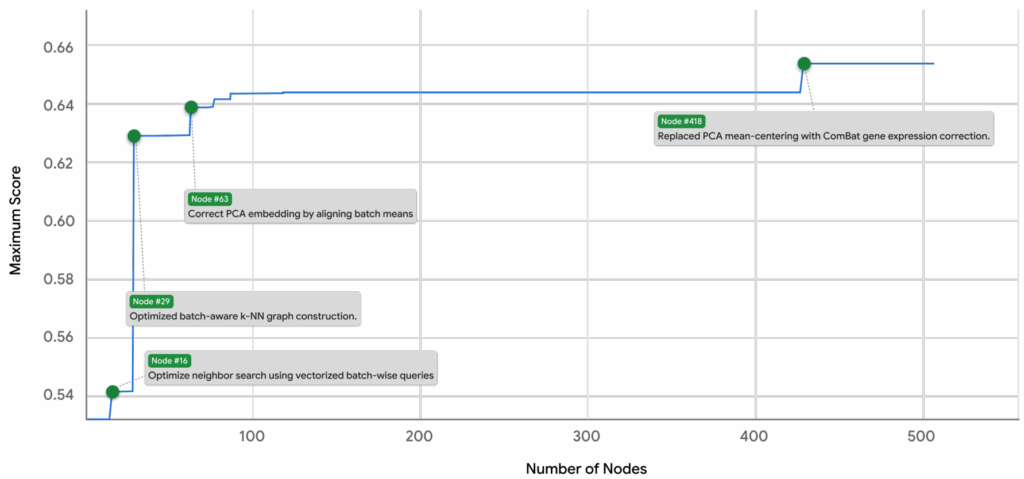
И вот ещё хорошая иллюстрация из статьи, которая показывает, как всё это работает вместе. Простите за большую картинку:
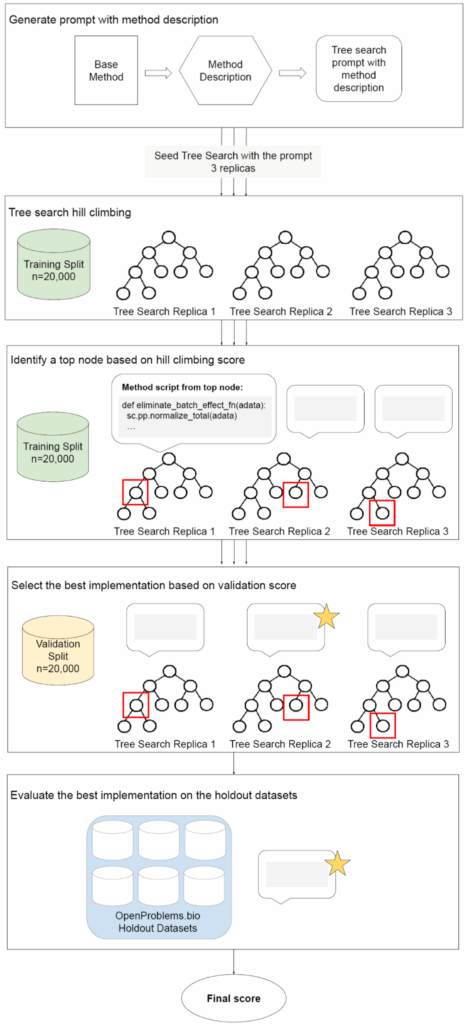
Инъекции и рекомбинации идей
После того как мы поняли общую идею MCTS для программ, начинается самая интересная часть, в которой интеллект современных LLM помогает сделать MCTS-поиск ещё лучше. Система Aygün et al. (2025) не просто мутирует код наугад — она, во-первых, импортирует идеи из внешних источников:
- из научных статей, из которых она берёт описания методов и превращает их в ограничения и промпты для порождения кода;
- из Gemini Deep Research, которую она использует для синтеза релевантных идей;
- из Google Co-Scientist, от которой она получает планы новых экспериментов.
Возвращаясь к примеру: вы даёте системе задачу сделать batch integration на некотором датасете из single-cell RNAseq. Она идёт, читает статьи про ComBat, BBKNN, Harmony и другие методы, извлекает ключевые идеи (“ComBat делает линейную коррекцию через эмпирический байес”, “BBKNN балансирует батчи в пространстве ближайших соседей”), а затем пытается комбинировать эти идеи при порождении нового кода.
Последняя важная часть системы — рекомбинация, которая приходит из генетических алгоритмов. Помните, как в биологии работает половое размножение? Берём гены от двух родителей, перемешиваем, иногда получаем потомство, которое превосходит обоих, закрепляем.
То же самое можно попытаться сделать и с алгоритмами. В обычном генетическом программировании это бы значило взять два синтаксических дерева и перемешать; вот иллюстрация из классического обзора Tettamanzi (2005):
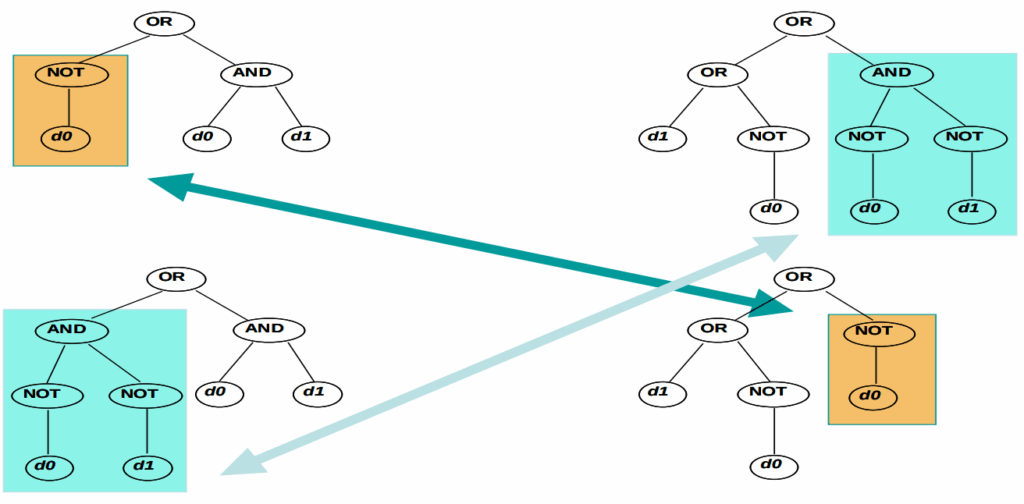
Но при помощи современных LLM Aygün et al. (2025) могут сделать рекомбинацию поумнее: взять два метода, которые хорошо работают, попросить LLM проанализировать их сильные и слабые стороны, добавить этот анализ в промпт и попросить породить гибрид, который пытается взять лучшее от обоих.
Звучит примитивно, но работает очень хорошо. В той самой задаче интеграции single-cell данных 24 из 55 гибридов (почти половина!) превзошли обоих родителей по получающейся оценке качества.
Можно даже разобрать конкретный весьма элегантный пример. Есть два классических метода для batch correction:
- ComBat (Johnson et al., 2007), который делает глобальную линейную коррекцию, используя эмпирический байес (кстати, вот моя лекция про эмпирический байес из прошлогоднего курса); насколько я понял, ComBat хорошо удаляет глобальные батч-эффекты из всего датасета сразу, корректируя PCA-вложениях данных; он был номером один в лидерборде до сих пор;
- BBKNN (Batch Balanced k-Nearest Neighbors; Polanski et al., 2020), напротив, работает локально, балансируя представленность батчей среди ближайших соседей каждой клетки.
Система составила из них гибрид, который сначала применяет ComBat для глобальной коррекции, а затем применяет BBKNN для тонкой локальной балансировки уже на глобально скорректированных PCA-вложениях. И этот гибрид стал лучшим методом на бенчмарке OpenProblems (Luecken et al., 2025), улучшив качество относительно оригинального ComBat на ~14%. В табличке ниже (TS) значит, что метод улучшили поиском по деревьям:
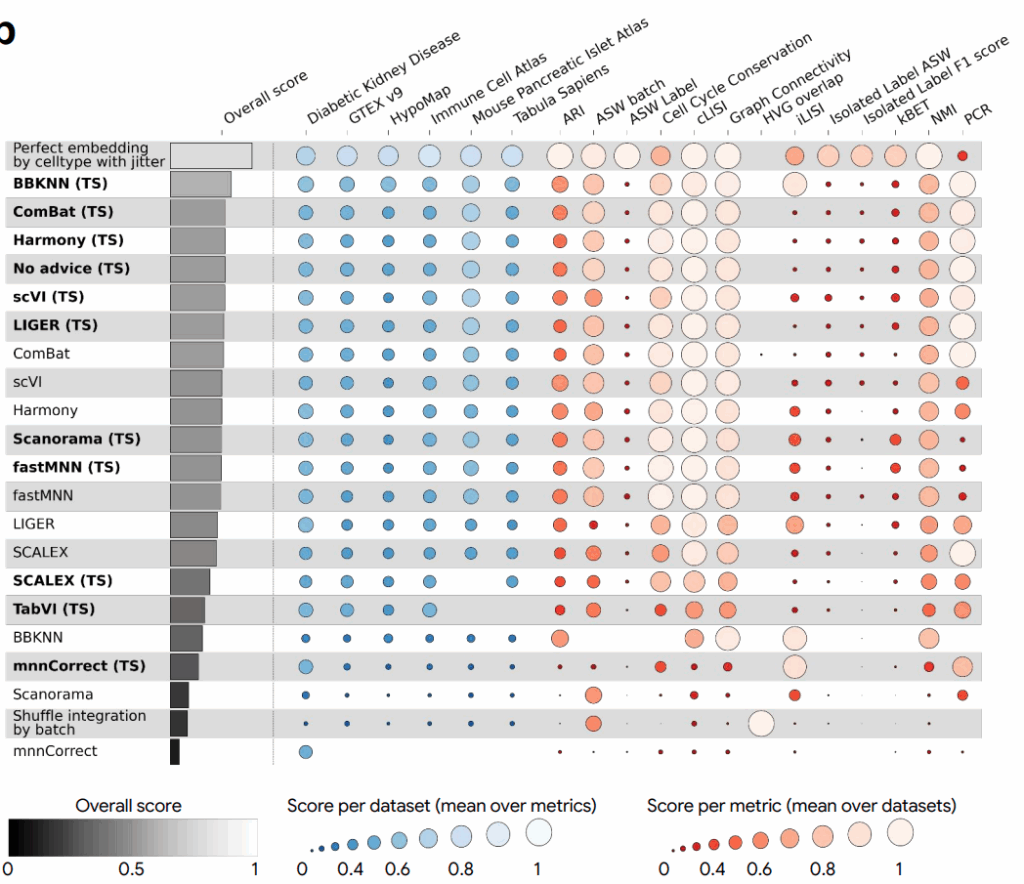
Мог бы человек додуматься до такой комбинации? Конечно! Сейчас, когда я прочитал о ней в статье и описал её здесь, эта идея звучит абсолютно тривиально. Но почему-то никто пока не успел посмотреть на проблему под таким углом, а система нашла этот угол автоматически, попутно протестировав десятки других вариантов.
Это как если бы у вас был аспирант, который прочитал всю литературу по теме, понял основные принципы и теперь систематически комбинирует их в поисках лучшего решения. Может быть, это пока не Эйнштейн, а всего лишь добросовестный аспирант, и у него нет блестящей научной интуиции, которая бы позволила сократить поиск до минимума. Но зато он очень, очень старательный, и может за одну ночь протестировать сотни вариантов.
Другие примеры
Я пока разбирал пример про single-cell РНК-секвенирование, но вроде бы система позиционируется как куда более общая; что насчёт других областей? Авторы рассматривают несколько разных задач, с весьма впечатляющими результатами.
Прогнозирование эпидемии COVID
Во время пандемии CDC (Centers for Disease Control and Prevention) собирали прогнозы госпитализаций от десятков исследовательских групп и объединяли их в ансамбль. Тогда это был золотой стандарт — лучшее, что могло предложить научное сообщество.
Что сделала система:
- воспроизвела 8 методов из CovidHub,
- породила новые подходы через MCTS,
- применила рекомбинацию к лучшим методам.
В результате 14 стратегий превзошли ансамбль CDC по метрике WIS (weighted interval score), и из них 10 — рекомбинации существующих методов.
Здесь особенно стоит подчеркнуть, что система работала с минимальными внешними данными — только исторические данные о госпитализациях. Никаких данных о мобильности, вакцинации, погоде и тому подобных условиях, которые некоторые системы вполне себе учитывали. И всё равно выиграла.
Прогнозирование нейронной активности у рыбок данио
Это очень интересная задача из нейробиологии, к которой я надеюсь ещё вернуться в будущем: предсказать активность нейронов в мозге рыбки данио (zebrafish; это модельный организм, для которого мы реально можем так или иначе измерить активность всех нейронов) по визуальным стимулам. Если бы мы в этой активности что-то поняли, это было бы очень важным шагом для понимания того, как мозг обрабатывает информацию.
Система создала два новых решения — не буду уж углубляться в детали, но, в общем, одно свёрточное, другое на основе FiLM-слоёв (Perez et al., 2018) — и оба метода заняли лидирующие позиции на бенчмарке ZAPBench. Причём два метода различались горизонтами — предсказание на один шаг и далеко вперёд — и действительно модель, которую система позиционировала как single-step, оказалась лучшей для предсказания на один шаг вперёд.
Предсказание временных рядов
На бенчмарке GIFT-Eval (92 временных ряда разной природы) система соревновалась с предобученными моделями Chronos от Amazon, TimesFM от Google и Moirai от Salesforce. Это foundational модели для временных рядов, большие и предобученные на терабайтах данных.
И здесь MCTS для каждого датасета создавал специализированные модели, которые были вполне конкурентоспособны с этими монстрами. Без гигантского предобучения, просто умным поиском в пространстве алгоритмов.
Неожиданный поворот: численное интегрирование
Это мой любимый пример, потому что он показывает универсальность подхода. Задача понятная: вычислить значения сложных интегралов. Не машинное обучение, не статистика — чистая вычислительная математика.
Здесь Aygün et al. (2025) сами создали датасет из 38 сложных интегралов. Под “сложными” подразумеваются интегралы, которые не решает стандартный scipy.integrate.quad: или расходится когда не надо, или просто возвращает неправильный ответ. На половине из них система оценивала MCTS, а другая половина была тестовой. Вот вам немного Демидович-вайба:

И в результате получилась специализированная процедура, которая решила 17 из 19 тестовых сложных интегралов с ошибкой менее 3%! Иначе говоря, подход работает не только для ML-задач. Любая задача, где есть код и численная метрика качества, может стать полем для таких исследований.
Заключение: ну что, расходимся, коллеги?
Прежде чем мы все побежим переквалифицироваться в курьеров, давайте обсудим ограничения.
Во-первых, не до конца ясно, насколько это лучше, чем обычный AutoML. Авторы утверждают, что да — и действительно, система меняет структуру алгоритмов, а не только гиперпараметры. Пример с ComBat+BBKNN это подтверждает. Но хотелось бы увидеть прямое сравнение: насколько упадёт качество, если ограничить систему только изменением гиперпараметров?
Во-вторых, здесь очень важна возможность быстро тестировать варианты, а также должно быть уже достаточно примеров разных подходов в литературе, чтобы было что комбинировать. Для exploratory research, где вы не знаете, что ищете, человек пока незаменим.
В-третьих, это всё, конечно, в чистом виде подгонка под бенчмарк. Самое главное, что требуется для успешной работы подобной системы — это целевая метрика, выражаемая одним числом. Новые идеи могут появиться как часть поиска, но оцениваться они будут исключительно по этим численным показателям.
С одной стороны, это вдохновляет: опять получается, что AI-системы опять автоматизируют рутину, только эта рутина выходит на следующий уровень. Представьте себе, что у каждого учёного появится этакий “code search assistant”. С ним учёный может выдвинуть новую идею, сделать один кое-как работающий proof of concept, а потом передать идею автоматической системе и сказать её: “а теперь выжми всё что можно на бенчмарках”. “Выжимание бенчмарков” — это сейчас большая часть работы учёных в прикладных областях, и не сказать что самая творческая или самая осмысленная.
С другой стороны, получается, что уровень “рутины” поднимается всё выше и выше. Да, конечно, пока всё это leaky abstractions — даже обычный научный текст, написанный LLM, всё ещё нужно проверять и править. Но всё-таки мы видим, что работают такие системы всё лучше, осваивая новые творческие уровни научной работы. А в науке ведь не нужно много девяток надёжности: если один из запусков системы даст новый хороший алгоритм, совершенно не страшно, что десять запусков перед этим не привели ни к чему…
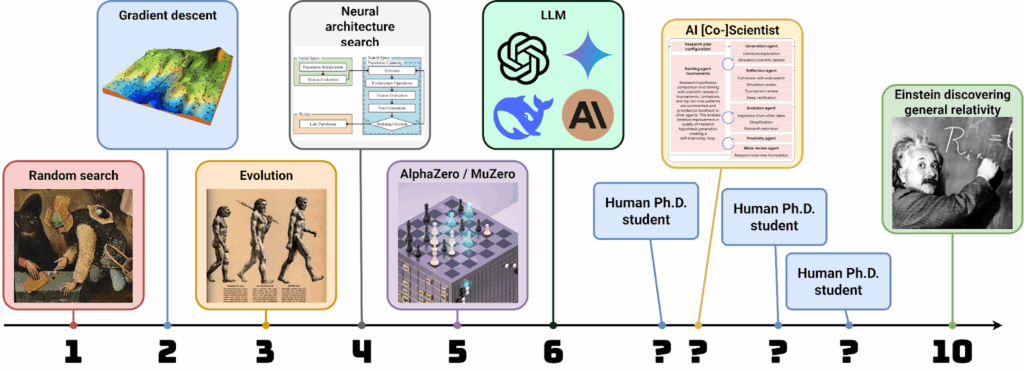
Пока ещё LLM — очень далеко не Эйнштейны. Но много ли уровней осталось, коллеги? Где мы сейчас на той самой шкале креативности, которую я когда-то рисовал?
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале “Sineкура”: присоединяйтесь!