AI в 2025, часть II: изображения и видео
1/18/2026

Введение
2025 год стал переломным не только для языковых моделей (о которых мы говорили в первой части), но и для всего, что связано с обработкой и порождением визуального контента. Если попытаться выделить главные темы этой части обзора в одном списке, получится примерно так:
- flow matching окончательно вытеснил классическое диффузионное обучение,
- 3D Gaussian splatting теперь доминирует в нейросетевом представлении сцен,
- фундаментальные модели наконец-то массово пришли в medical imaging и теперь меняют медицину на практике.
Но, пожалуй, самый важный архитектурный сдвиг 2025 года — это замена итеративной оптимизации на прямые нейросетевые предсказания (feedforward prediction). Раньше многие задачи компьютерного зрения решались через многошаговые алгоритмы: сначала найти ключевые точки, потом сопоставить их между кадрами, потом оптимизировать позы камер… Теперь всё чаще одна нейросеть делает всё это за один проход. Это не просто удобнее, но ещё и быстрее, иногда буквально на порядки.
Давайте разберёмся детальнее, что именно произошло.
Порождающие модели для изображений и видео
Потребительские модели: война гигантов
Порождение изображений в 2025 году совершило качественный скачок. В марте OpenAI фактически упразднила DALL-E 3, заменив её на порождение изображений внутри GPT-4o. Это была не просто замена одной модели на другую, а творческое переосмысление самой архитектуры.
GPT-4o порождает изображения как часть своего мультимодального понимания мира: модель помнит контекст разговора, может итеративно уточнять картинку по вашим комментариям, и вообще ведёт себя так, как будто рисование — это просто ещё один способ ответить на вопрос.
Но монополия OpenAI продержалась недолго. В августе Google выпустил Gemini 2.5 Flash Image, получивший название Nano Banana. Эта модель порождала изображения примерно в три раза быстрее GPT-4o, и при этом была способна делать консистентных персонажей и реалистичные лица с минимумом артефактов. В ноябре вышла Pro-версия на базе Gemini 3, добавившая 4K-разрешение и, что особенно важно, отличный рендеринг текста на любом языке и в любом стиле.
OpenAI ответил в декабре моделью GPT-Image-1.5, которая в четыре раза быстрее предшественницы. Сейчас сложилась интересная ситуация: ChatGPT остаётся единственным инструментом с “идеальным” порождением текста на изображениях, а Nano Banana Pro лидирует в разрешении и в управляемости, т.е. в том, насколько хорошо она реагирует на детали промпта. Видимо, практическая рекомендация здесь в том, чтобы использовать обе модели, сочетая их сильные стороны.
“ChatGPT-момент” в порождении видео
Это, конечно, субъективное мнение, но мне кажется, что в 2025 году порождение видео пережило свой собственный “ChatGPT-момент” — тот переломный момент, когда технология из предмета в основном научных статей превращается в инструмент массового использования.
Sora 2 от OpenAI (сентябрь 2025) добавила к видео синхронизированный звук: диалоги, музыка и звуковые эффекты порождаются теперь прямо в сцене. Добавьте к этому более точную симуляцию физики, сохранение состояния мира между кадрами и функцию “Cameo” для вставки конкретных лиц. Главным подтверждением зрелости этой технологии стала сделка с Disney в декабре: миллиард долларов инвестиций и трёхлетняя лицензия на использование персонажей. Когда Disney вкладывает такие деньги — это сигнал, что мейнстрим-индустрия развлечений готова к порождающим моделям.
Google не отстаёт: Veo 3 (май 2025) и Veo 3.1 поддержали почин Sora в синхронизации звука, а Демис Хассабис красиво сказал о выпуске этих моделей: “AI-порождение видео покидает эру немого кино”. За несколько месяцев после запуска было сгенерировано более 70 миллионов видео.
Среди менее крупных игроков стоит выделить Runway, который с Gen-4.5 и General World Model (GWM-1) продвигает исследуемые в реальном времени среды и разговорные аватары, и Pika Labs, где продолжают делать инструменты для порождения видео более доступными для обычных пользователей.
Под капотом: от диффузии к flow matching
А теперь давайте заглянем под капот. Что изменилось в математике генеративных моделей?
Если коротко: flow matching (сопоставление потоков) окончательно вытеснил дискретные марковские цепи в обучении диффузионных моделей. Чтобы понять разницу, нужно немного углубиться в теорию.
Классическая диффузия работает так: мы берём изображение и постепенно добавляем к нему шум по дискретным шагам, пока не получим чистый гауссовский шум. Затем обучаем нейросеть предсказывать шум на каждом шаге, чтобы она могла «отмотать» процесс назад — от шума к изображению. Об этом я рассказывал, например, в посте с объяснением диффузионных процессов.
Проблема в том, что дискретные шаги требуют много итераций при порождении (20-50 шагов даже со всеми оптимизациями), и каждый шаг — это проход через тяжёлую нейросеть.
Flow matching переформулирует задачу в терминах непрерывной динамики. Вместо дискретных шагов диффузии мы определяем непрерывное векторное поле скоростей, которое переносит распределение шума в распределение данных. А нейросеть учится предсказывать это поле скоростей. Математически это эквивалентно решению обыкновенного дифференциального уравнения, что позволяет использовать численные методы, разрабатывавшиеся в этой науке столетиями, и в результате порождать изображения за гораздо меньшее число шагов.
Рекомендую, например, вводный обзор от MIT (Holderrieth и Erives, июнь 2025), в котором в том числе показано, что для гауссовских источников flow matching и диффузионные модели математически эквивалентны — разница только в параметризации выхода сети и расписании шума. Но на практике flow matching часто проще обучать, и порождение получается гораздо быстрее.
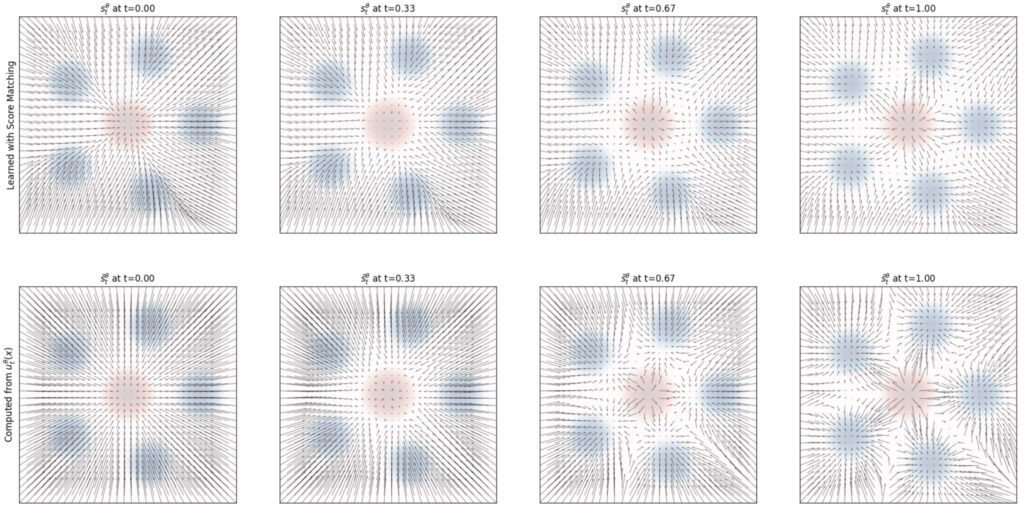
Например, работа Diff2Flow (Schusterbauer et al., июнь 2025) связывает эти парадигмы: авторы показывают, как вывести поле скоростей для flow matching из предсказаний диффузионной модели. Это позволяет переиспользовать уже обученные модели вроде Stable Diffusion в режиме flow matching.

А недавний теоретический анализ от Liu et al. (декабрь 2025) выявил интересную двухфазную динамику в потоковых моделях: сначала происходит фаза “навигации”, управляемая смесью данных, а потом вторая фаза “уточнения”, где доминируют ближайшие примеры из обучающей выборки.

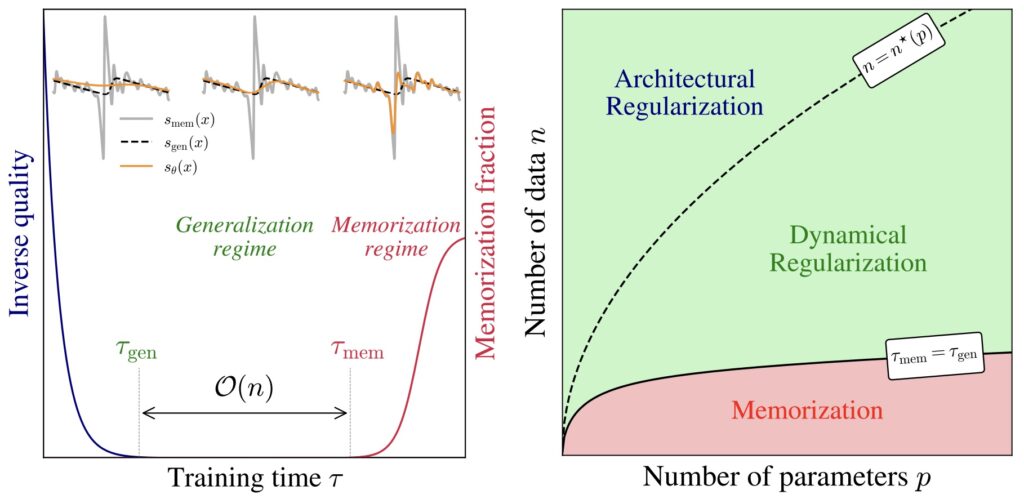
А одна из статей, признанных лучшими на NeurIPS 2025 — “Why Diffusion Models Don’t Memorize” (Bonnaire et al., май 2025) — отвечает на естественный, но оказавшийся весьма сложным вопрос: почему диффузионные модели с их гигантской ёмкостью не запоминают просто обучающую выборку? Где оверфиттинг?
Ответ оказался красивым: сам процесс итеративного денойзинга действует как неявный регуляризатор. Используя теорию случайных матриц, авторы нашли в обучении два этапа: фаза обобщения, не зависящая от размера датасета, за которой следует фаза запоминания, линейно зависящая от размера данных.
Продолжаются также улучшения в моделях, основанных на выпрямленных потоках (rectified flows); здесь Yang et al. (февраль 2025) предложили метод RFDS (Rectified Flow Distillation Sampling), похожий на функцию ошибки SDS в обычной диффузии:

Революция масштабирования в диффузионных трансформерах
Архитектура Diffusion Transformer (DiT) окончательно заменила U-Net в порождающих моделях. Вытеснение началось ещё в 2024 году с работ вроде Dynamic Diffusion Transformer (DyDiT; Zhao et al., октябрь 2024) и Representation Alignment для порождения (REPA; Yu et al., октябрь 2024), а в 2025 году переход полностью закончился.
Например, EC-DIT от Apple (Sun et al., январь 2025) масштабировался до 97 миллиардов параметров, используя Mixture-of-Experts с новыми алгоритмами маршрутизации. Идея в том, что разные части изображения требуют разного количества вычислений — простой фон обрабатывается “дешёвыми” экспертами, а сложные детали — “тяжёлыми”.
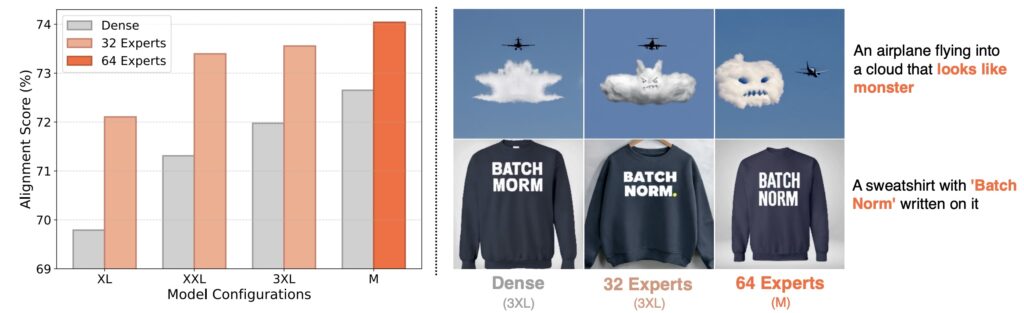
Другая интересная и важная — улучшение эффективности обучения через перенос гиперпараметров (Zheng et al., май 2025). Они обобщили технику Maximal Update Parametrization (μP), которая позволяет переносить гиперпараметры от маленьких моделей к большим, с обычных LLM, для которых она изначально предназначалась (см., например, этот обзор) на архитектуры DiT. В результате DiT-XL-2-μP сходится в 2.9 раза быстрее, а масштабирование MMDiT с 0.18B до 18B параметров потребовало всего 3% от обычных затрат на дообучение:
Все главные видеогенераторы 2025 года — Sora 2, CogVideoX, HunyuanVideo (13B параметров), FLUX — теперь используют архитектуры, основанные на DiT. Можно сказать, что U-Net как архитектура для диффузионных моделей окончательно устарела.
AI в 3D: порождение и распознавание сцен и объектов
Лучшие статьи CVPR 2025 посвящены 3D
Поскольку я всё-таки в первую очередь учёный, мне кажутся важными сигналы в виде того, что объявляется лучшими статьями соответствующих конференций. И вот best papers на CVPR 2025 оказались посвящены именно работе с 3D.
Так, best paper получила работа “VGGT: Visual Geometry Grounded Transformer” от команды Oxford VGG и Meta AI (Wang et al., март 2025). Чтобы понять, почему это важно, нужно немного контекста. Традиционная 3D-реконструкция из нескольких 2D-изображений — это сложный многостадийный пайплайн: калибровка камер, сопоставление признаков между кадрами, bundle adjustment (совместная оптимизация позиций камер и 3D-структуры) и так далее. На каждом этапе могут накапливаться ошибки, каждый требует тщательной настройки.
А VGGT делает всё это одной нейросетью. Один трансформер принимает на вход от 1 до 100 изображений и выдаёт настройки камер, карты глубины и соответствия между изображениями, за считанные секунды. Это тот самый переход от итеративной оптимизации к feedforward-предсказаниям, который я упоминал в начале.

А Best Student Paper на CVPR 2025 получила “Neural Inverse Rendering from Propagating Light” (Malik et al., июнь 2025) — работа на стыке компьютерного зрения и физики. Обратный рендеринг — восстановление геометрии, материалов и освещения из фотографий — это классическая некорректная задача (ill-posed problem). А здесь авторы вводят дифференцируемую формализацию переноса света, которая позволяет делать градиентную оптимизацию и проводить физически корректную декомпозицию сцены.
От NeRF к Gaussian Splatting
После бума NeRF (Neural Radiance Fields) в 2020-2022 годах казалось, что нейронное представление сцен нашло свой “правильный” формат. Но в 2025 году всё опять перевернулось: теперь убедительно побеждает 3D Gaussian Splatting (3DGS).
Давайте разберёмся, в чём разница. NeRF представляет сцену как непрерывную функцию: для любой точки пространства и направления взгляда нейросеть выдаёт цвет и плотность. Чтобы отрендерить изображение, нужно «прострелить» лучи через каждый пиксель и проинтегрировать вдоль них — это медленно, секунды на кадр даже в лучшем случае.
3D Gaussian Splatting представляет сцену как облако трёхмерных гауссианов — “размытых” точек, задаваемых центром, матрицей ковариаций, цветом и прозрачностью. Вот наглядное сравнение из давнего обзора Chen, Wang (2024):
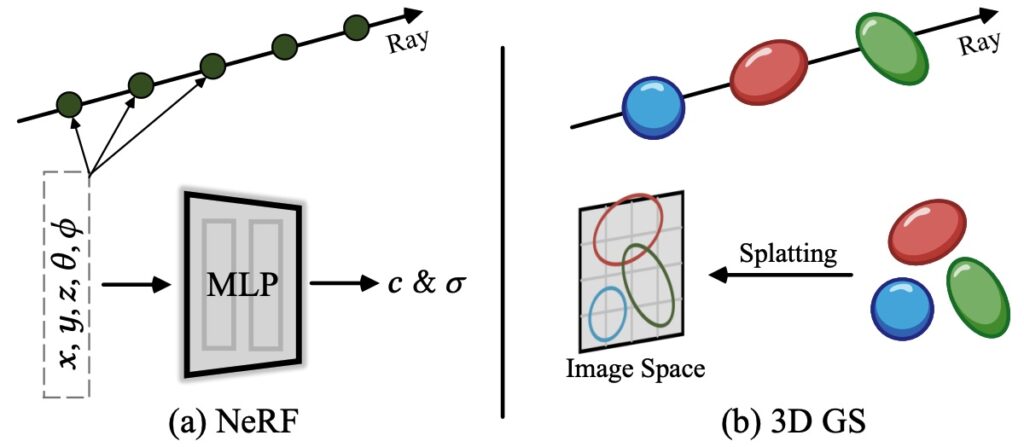
Теперь рендеринг — это проекция этих гауссианов на плоскость изображения. Это можно делать параллельно на GPU, получая сотни FPS в реальном времени.
Но дело не только в скорости рендеринга. 3DGS обучается за минуты (NeRF — за часы), и его можно напрямую редактировать: двигать гауссианы, удалять их, добавлять новые.
Например, работа “NeRF Is a Valuable Assistant for 3D Gaussian Splatting” (Fang et al., июль 2025) отражает новую реальность: NeRF-техники теперь дополняют 3DGS, а не конкурируют с ним, предоставляя инициализацию (с нуля 3DGS обучить трудно) и регуляризацию.
А Honourable Mention на CVPR получила работа “3D Student Splatting and Scooping” (SSS; Zhu et al., март 2025). Авторы исправили две главные проблемы 3DGS: тенденцию к переобучению с избыточным числом гауссианов и сложности с высокодетализированными структурами. В SSS вводится операция scooping, которая удаляет лишние гауссианы, а сеть-ученик обучается строить более эффективное представление:


Слабое место Gaussian Splatting — затраты памяти. Для сложных сцен нужны миллионы гауссиан, что занимает гигабайты на каждую сцену. Но в 2025 году случились серьёзные продвижения и в методах сжатия.
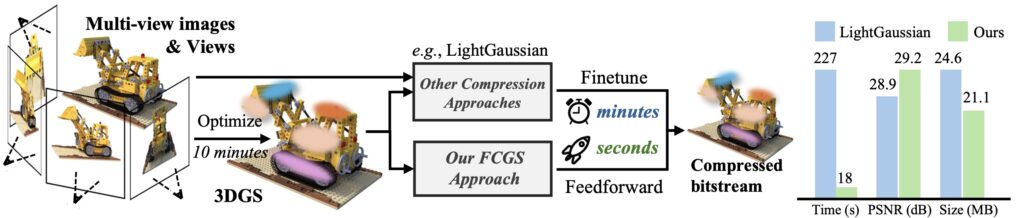
Например, метод HAC++ (Chen et al., январь 2025) достигает 100-кратного сжатия через моделирование контекста на hash grids, а FCGS (Fast Feedforward 3DGS Compression; Chen et al., Jan 2025) сжимает в 10 раз быстрее предыдущих методов, не требуя при этом решать задачи оптимизации:
Модель 3DGUT от NVIDIA (Wu et al., март 2025) поддерживает искажённые камеры (fisheye, rolling shutter) и вторичные лучи (отражения), давая при этом 250+ FPS через Unscented Transform:

А generative sparse-view Gaussian splatting (GS-GS; Kong et al., Jun 2025) позволяет делать высококачественную детальную реконструкцию по всего трём обучающим изображениям. Вот пример результата в сравнении с обычным Gaussian splatting (слева), что довольно наглядно показывает прогресс за минувший год-полтора:

Динамические сцены и 4D
Временные расширения 3DGS позволяют захватывать и динамические, изменяющиеся во времени сцены. Например, Anchored 4D Gaussian Splatting (Li et al., декабрь 2025) использует якорные точки для регуляризации временных атрибутов гауссианов:
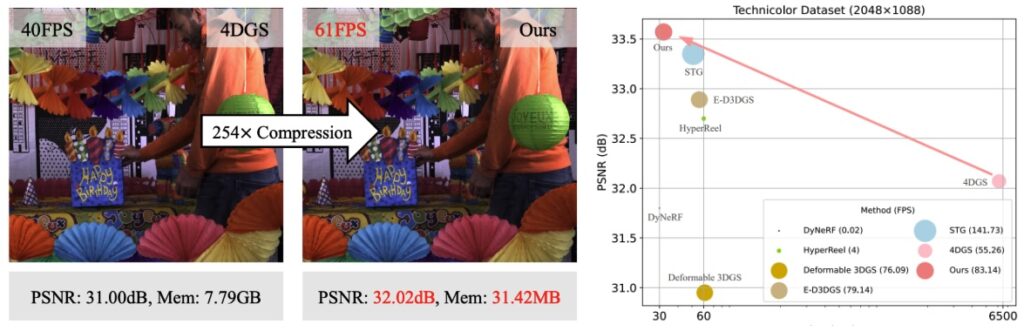
MEGA (Zhang et al., июль 2025) — это прорыв в эффективности памяти; например, для показанной на картинке сцены “Birthday” число требующихся гауссианов сократилось с 13M до 0.91M, а общий объём памяти — с 7.79GB до менее 1GB:
Но, пожалуй, самое интересное — feedforward-подходы. Diff4Splat (Pan et al., ноябрь 2025) синтезирует 4D за 30 секунд через video latent Transformer без оптимизации на инференсе:

Этот обзор можно было бы продолжать бесконечно, но где-то всё-таки нужно остановиться. Давайте я просто напоследок порекомендую этот сборник ссылок, в котором уже около 500 статей только о Gaussian splatting.
Text-to-3D за секунду
Пайплайн text-to-3D, то есть порождение 3D-сцен по текстовым промптам, тоже сильно изменился в 2025 году. И здесь тоже основным сдвигом было существенное ускорение процесса за счёт feedforward подходов.
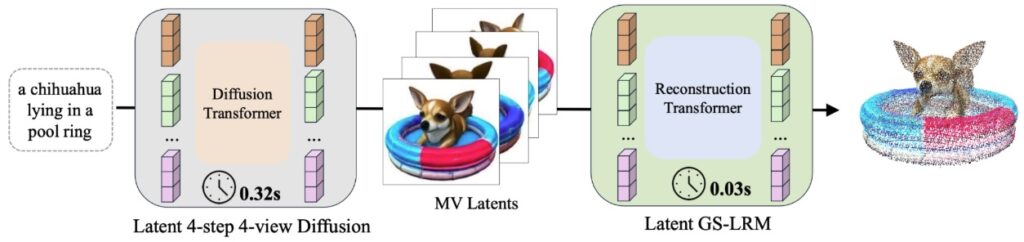
Turbo3D (CVPR 2025, Hu et al., декабрь 2024) может порождать 3D-сцены менее чем за секунду: по сути это четырёхшаговая, 4-view (с четырёх видов) диффузия плюс реконструкция гауссианов в латентном пространстве. Использованные там методы обучения (dual-teacher distillation) обеспечивают и консистентность между разными видами, и (насколько это возможно) фотореалистичность:
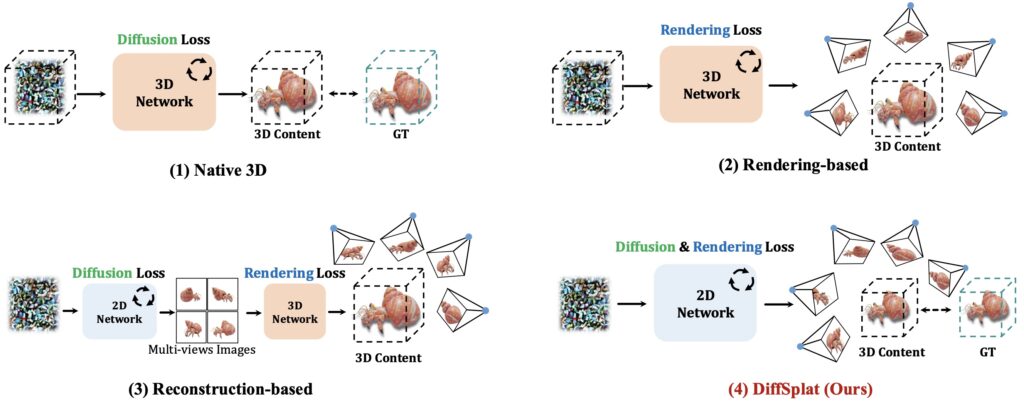
DiffSplat (Lin et al., январь 2025) генерирует 3D-гауссианы напрямую из text-to-image диффузионных моделей за 1-2 секунды, предлагая специальный 3D rendering loss для того, чтобы поддерживать соответствие между разными видами:
А во второй половине 2025-го мы увидели, как этот (во многом академический) прогресс начал масштабироваться и превращаться в мощные инструменты.
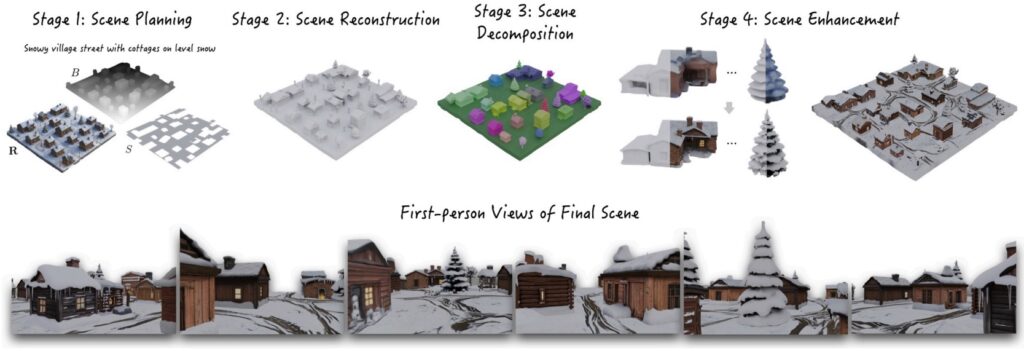
Например, модель WorldGen (Wang et al., ноябрь 2025) пытается делать полноценное порождение целых 3D-миров по текстовому запросу, создавая среды размеров 50х50 виртуальных метров, по которым можно потом реально передвигаться:
Кажется, мы уже на этапе, когда можно быстро генерировать 3D-ассеты из текстового описания, но пока не на этапе, когда эти ассеты можно использовать as is в игре или VR-среде. Посмотрим, какой будет прогресс в ближайшем будущем.
Распознавание медицинских снимков
Из многочисленных приложений компьютерного зрения я выберу это, потому что и сам когда-то делал нечто подобное, да и вообще кажется, что с точки зрения улучшения нашей с вами жизни всё-таки трудно придумать что-то более важное, чем медицина.
Как мы говорили выше, в 3D-порождении мы на стадии “почти продакшен”. А вот в распознавании медицинских снимков AI-модели давно уже полностью готовы к любому “продакшену” и во многих задачах превосходят врачей — но не использовались широко из-за регуляторных барьеров и проблем с распределением ответственности.
И вот наконец, похоже, барьеры падают. По данным Imaging Wire (декабрь 2025), FDA одобрило более 1356 устройств с AI-моделями к сентябрю 2025 года, из них более тысячи — для радиологии (77% от всех).
Вот несколько важных примеров из 2025 года:
- Philips SmartSpeed Precise (июль) — первое интегрированное решение с AI-моделями, помогающими МРТ: сканирование быстрее в 3 раза, изображения чётче на 80%;
- ArteraAI Prostate (июль) — AI-решение для распознавания рака простаты с первым в истории “predetermined change control plan” для цифровой патологии (это важный регуляторный прецедент);
- Galen Second Read (февраль) — тоже AI для обнаружения рака.
В медицине я, конечно, вообще не эксперт, так что углубляться не буду, но обзоры развития патологии в 2025 году называют его “годом индустриализации” — наконец-то пошло массовое внедрение в реальную медицину.
Фундаментальные модели тоже переходят от исследований к внедрению. Например, MedSegX (Zhang et al., сентябрь 2025) использует Contextual Mixture-of-Adapter-Experts для сегментации 39 органов и тканей. Рекомендую здесь обзор от van Veldhuizen et al. (июнь 2025), покрывающий более 150 исследований фундаментальных моделей для патологии, радиологии и офтальмологии.
Разное
В области изображений и 3D-сцен порождающие модели, конечно, затмевают всё остальное. Но “классические” задачи компьютерного зрения тоже остаются важными. В этом разделе я очень кратко пройдусь по главным работам 2025-го в этих направлениях; это скорее перечисление, чем подробный рассказ.
Распознавание документов и видео
DeepSeek-OCR (Wei et al., октябрь 2025) вводит метод “contextual optical compression” — сжатие документов в компактные визуальные токены с сохранением пространственной привязки.
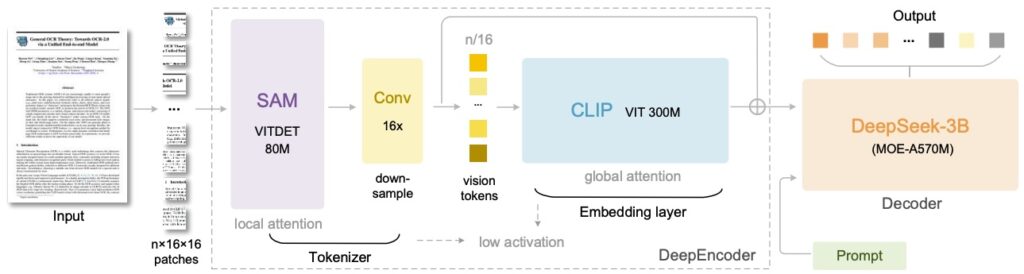
Это даёт около 97% точности декодирования при 10-кратном сжатии и позволяет обрабатывать более 200 тысяч страниц в день на одной A100.
Понимание видео за масштабировалось до роликов длиной около часа. Здесь хочется выделить семейство моделей Video-XL, которое появилось в 2024 году (Shu et al., Sep 2024), а в 2025-м было продолжено в виде Video-XL-2 (Qin et al., июнь 2025), где предлагается так называемый метод task-aware KV sparsification, новый вариант разреженного внимания.
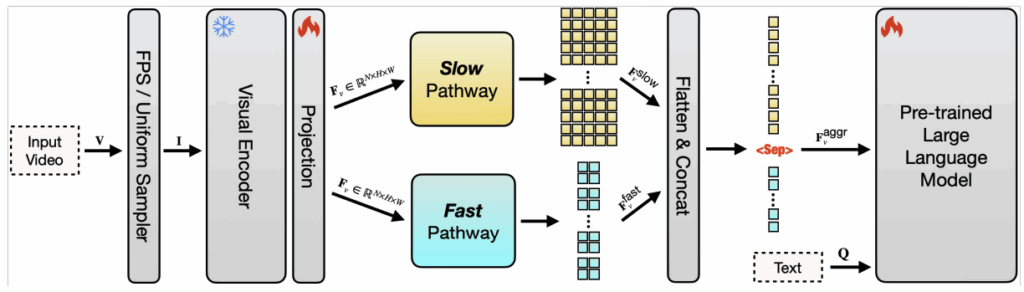
В работе Hour-LLaVA/VideoMarathon (Lin et al., июнь 2025) представлен датасет понимания видео на 9,700 часов с 3.3M парами вопрос-ответ. А разработанная в Apple модель SlowFast-LLaVA-1.5 (Xu et al., март 2025) улучшает результаты на LongVideoBench через двухпоточную архитектуру: медленный поток для пространственных деталей и быстрый поток для временной динамики.
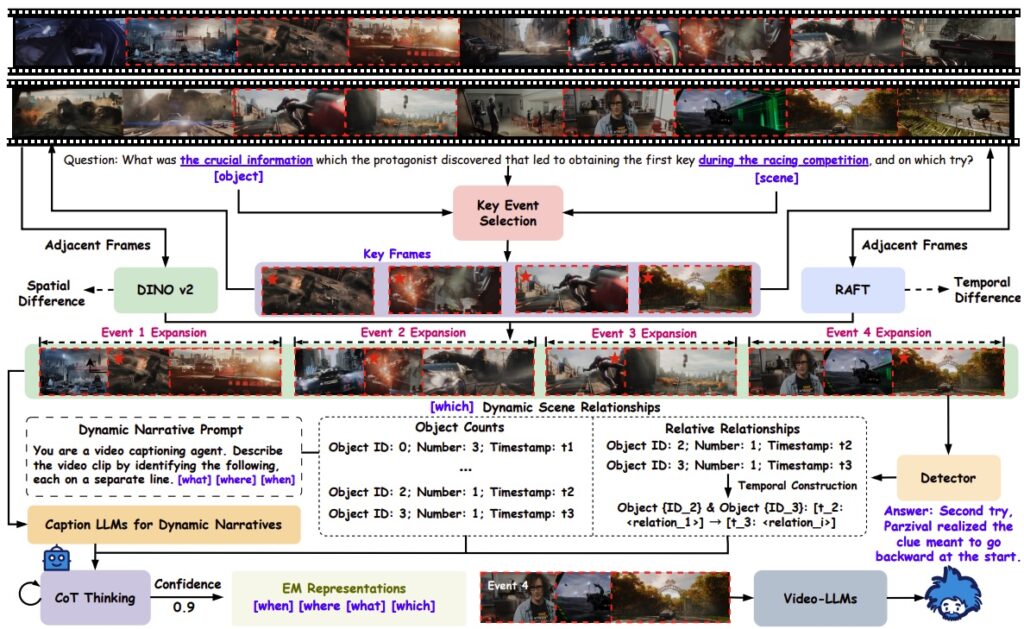
Интересная работа Video-EM (Wang et al., август 2025) комбинирует идеи эпизодической памяти человека и video reasoning с chain-of-thought для работы с длинным контекстом:
А, например, Video-RAG (Ren et al., Feb 2025) расширяет retrieval-augmented generation (RAG) на многочасовые видео, связывая видео с текстовыми знаниями в виде графов и обучая мультимодальные представления контекста.
Сегментация: семейство SAM продолжает развиваться
В 2023 году модель Segment Anything (SAM; Kirillov et al., 2023), можно сказать, “решила” задачу сегментации и до сих пор даёт отличную основу для более сложных моделей. Обратите внимание, например, что упомянутый выше DeepSeek-OCR на первом этапе использует как раз SAM. Но исследования продолжаются для более сложных и общих задач.
SAM 2 (Ravi et al., январь 2025) расширил сегментацию на видео, добавив в архитектуру потоковую память, что сделало инференс в 6 раз быстрее. Они также выложили датасет SA-V с 50.9K видео и 35.5M масок сегментации.
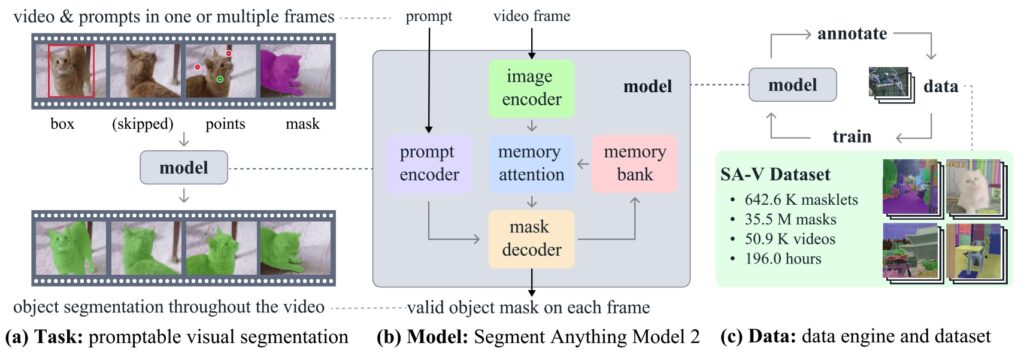
А в модели SAM 3 (Carion et al., ноябрь 2025) появился метод Promptable Concept Segmentation: текстовые промпты типа “жёлтый школьный автобус” приводят к сегментации всех подходящих объектов на изображениях и видео.

Архитектура SAM 3 на 848M параметров с декодером на основе DETR и presence tokens для различения близких концептов показывает, что даже в конце 2025 года ещё можно найти кое-какие новые идеи даже в такой избитой задаче, как сегментация:
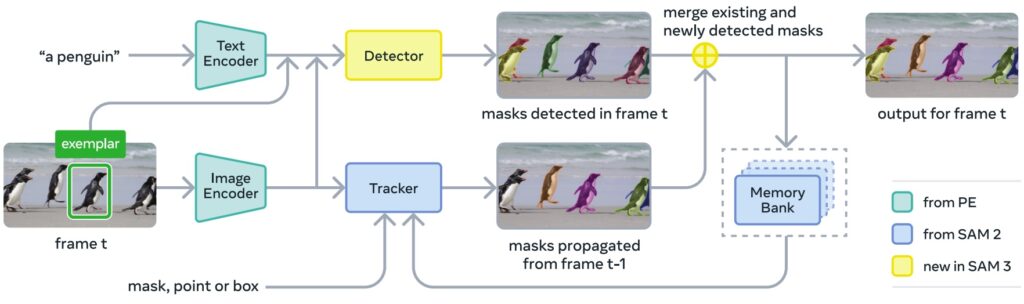
Редактирование изображений
Здесь просто упомяну пару интересных работ. Region-Aware Diffusion (RAD; Kim et al., CVPR 2025) — это вариант диффузионного процесса, в котором диффузия идёт по-разному в разных регионах изображения, что сильно ускоряет редактирование изображений:

TurboFill (Xie et al., апрель 2025) адаптирует few-step text-to-image модели для быстрого дополнения изображений (inpainting), а модель HD-Painter (Manukyan et al., январь 2025) даёт inpainting высокого разрешения по текстовому промпту.
Методы переноса стиля продолжали развиваться, например, в модели StyDiff, где AdaIN-слои добавили в диффузионную модель (Sun, Meng, Sep 2025). А для реставрации изображений вышла интересная модель Defusion (Luo et al., июнь 2025).
Выводы и заключение
Итак, каковы же были главные технологические сдвиги 2025 года в обработке изображений?
Замена итеративной оптимизации на feedforward-предсказания — это, на мой взгляд, главный архитектурный тренд 2025 года. В этом посте мы увидели его в VGGT (3D-реконструкция), Turbo3D (text-to-3D), FCGS (сжатие), Diff4Splat (4D-синтез). Каждый раз суть в общем-то одна: многошаговый алгоритм заменяется на одну нейросеть, и скорость растёт на порядки.
Это не просто инженерное удобство — это фундаментальный сдвиг в том, как мы решаем задачи компьютерного зрения. Вместо того чтобы разрабатывать алгоритмы, мы учим нейросети имитировать результат этих алгоритмов (или превосходить его); нечто подобное уже происходило в компьютерном зрении раньше, но сейчас выходит на новый уровень. Алгоритмы становятся данными для обучения.
Ещё один важный тренд — конвергенция модальностей. GPT-4o и последующие LLM порождают изображения как “ещё один способ ответить”. Sora 2 генерирует звук в контексте видео. SAM 3 сегментирует по текстовому описанию. Границы между модальностями размываются, и мы движемся к по-настоящему мультимодальным системам.
В следующих частях обзора мы поговорим о foundation vision-language models и world models (моделях мира) более подробно. А пока просто констатирую, что мы быстро движемся ко всё более общему визуальному искусственному интеллекту. 2026-й обещает быть ещё интереснее.
Сергей Николенко
P.S. Прокомментировать и обсудить пост можно в канале «Sineкура»: присоединяйтесь!